スレッド化の課題
正確性
最も一般的なスレッド化の問題の 1 つに、2 つのスレッドが同じデータを修正しようとする競合状態があります。データ要素の修正は、通常、アトミック操作ではないため、両方のスレッドが値を読み取り、更新し、書き込むことが可能です。このような場合、編集内容は他方のスレッドによって上書きされてしまいます。競合状態は稀にしか発生しないため、検出は非常に困難で再現も困難です。Intel の ThreadChecker などのツールは、競合状態の検出に適しています。これらを使用すると、実際に発生している競合状態、発生する可能性が高い状態の両方を検出できます。
競合状態が発生すると、必ず不正な結果が生じます。他にも重要度はやや低くなりますが、スレッド化コードで発生する可能性のある問題があります。たとえば、浮動小数点演算で精度が異なる問題です。減算演算を使用して値をさまざまなスレッドで累積してから集計する場合、四捨五入が異なるため、スレッドの数が最終結果に影響を与える場合があります。
#pragma omp parallel for reduction(+: sum) for ( int i = 0 ; i < n ; i++ ) sum += x[i]*y[i];
これは、小さな差異が時間とともに積み重なっていくようなシミュレーションでは重大な影響を及ぼす可能性があります。以下は、ある場所で上記と同様のコードをコールした Maya 流体ソルバの初期スレッド化実装の 2 つのイメージです。この 2 つの唯一の違いはシステム上のコアの数です。したがって、ソルバで使用されるスレッドの数も異なります。いずれの結果も不正ではありませんが、四捨五入の違いによる外観の違いは明白です。


この問題を回避する方法はいくつかあります。1 つは一時的に精度を高くする方法です。たとえば、スレッド化計算時に倍精度に変更します。スレッド化の利点は、高精度の計算によるパフォーマンスへの影響を上回ります。別の方法としては、データをコンパイル時に修正されるチャンクに分割して実行時にスレッドに割り当ててから、整合性のある順序でその合計を累積します。これにより、分割したチャンクのサイズがまったく変更されないため、最終合計は常に同じになります。
一部の C/C++ ライブラリ関数は、内部状態を維持するためにスレッドセーフではありません。たとえば、STL コンテナ(STL コンテナの読み取りもスレッドセーフでない場合があります)、strtok() などの C 関数、多くの埋め込み型乱数ジェネレータなどがあります。これらをスレッド化コードからコールする場合は注意が必要です。TBB には STL の代替コンテナとしてスレッドセーフなコンテナが用意されており、Linux と OSX では _r 接尾辞(リエントリー用)、または Windows では _s 接尾辞が関連付けられる多くの C 関数のスレッドセーフな実装があります。たとえば、strtok_r() は strtok() のスレッドセーフなバージョンであり、strtok_s() は Windows での同等のスレッドセーフな関数です。残念ながら現在のところ、これらのスレッドセーフな関数にはクロスプラットフォーム標準がありません。
拡張性
アムダールとグスタフソン
アムダールの法則は、問題の規模が固定されている場合、最終的にコードの順次処理部分が大きく影響して拡張性が制限されてしまうため、スレッド数を増加してもそれに応じたパフォーマンスの向上率は得られないという考えです。
グスタフソンの法則は、通常、スレッド数は大規模な問題に対処するために増加されるのであって、問題の規模が固定されているというよりは実行時間が固定されているとする考えです。この場合、順次コードに対する並列コード処理の割合が問題の規模とともに増大するという条件では、パフォーマンスの向上率は無限に増加し続けます。
Maya のようなアプリケーションでは、前者よりも後者に近いため、適切に作成されたアルゴリズムであれば時間とともに拡張性の増大が期待できます。以下に、問題の規模が拡張性の向上につながることを示す流体ソルバの例を示します。
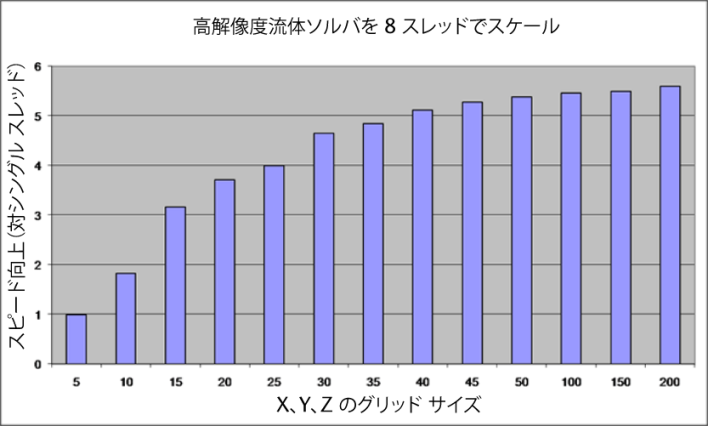
スレッド化のオーバーヘッド
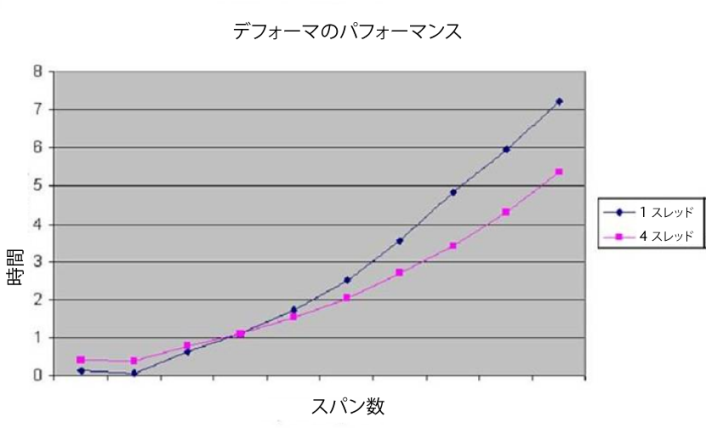
スレッド プールが有効になるオーバーヘッドは約 1 万サイクルです。したがって、評価のためにこのサイクル数に近い計算を行うとスレッド化の意味がなくなります。トリップ数が大きく変化し、ループが何度もコールされるような場合、パフォーマンスへの影響を回避するために、カットオフを明示的に下げると効果が期待できます。以下の図は、Maya デフォーマで小規模モデルを使用したスレッド化コードと非スレッド化コードのパフォーマンスを示しています。最小規模ではスレッド化のオーバーヘッドの影響が非常に大きく、実際にシングル スレッド化コードがマルチスレッド化コードよりも高速です。したがって、グラフの交点より下ではスレッド化が無効になりました。
拡張性に関しては、スレッド数の増加につれてロックが高価になるという問題もあります。このため、可能なかぎりロックを使用しないか、以前よりコア数の多いマシンでアプリケーションを実行する場合は、少なくともそのアプリケーションのプロファイルを再度設定してください。コアを 4 つに拡張するアルゴリズムでは適切に拡張されないか、または 8 つ拡張すると処理速度が低下することさえあります。
ロード バランシング
一部のループでは繰り返しごとに処理が大きく異なります。たとえば、メッシュの頂点のサブセットを操作するツール、または空のセルがあるボリュームでの流体ソルバの処理では、実行する処理がほぼないかまったくない繰り返しもあります。このような場合、スレッド間で要素数を均等に分割するぐらいしか選択の余地がありません。そのため、OpenMP のガイド付きまたはダイナミック スケジュール設定や TBB といったより均一に処理を配分できるアルゴリズムや実装を検討することも有用です。
偽共有
プロセッサは、要求されたデータをローカル キャッシュに読み取ることで処理をキャッシュします。ただし、ロードされる実際のデータだけではなく、データ項目の全体的なデータのキャッシュ ラインが読み取られます。キャッシュ ラインのサイズは通常 64 バイトですが、この値は保証されていません。
偽共有とは、キャッシュへの読み取り時に同じキャッシュ ラインに常駐するメモリー内の近接した位置にある変数に対して、複数のスレッドが読み書きを行う状態を示します。1 つのスレッドがこのような 1 つの変数に書き込みを行うと、キャッシュ ライン全体がプロセッサ キャッシュに読み取られます。このとき、別のスレッドが他のデータ要素を修正しようした場合、そのデータは、最初のプロセッサ キャッシュからより低レベルのキャッシュまたはメイン メモリに書き込んでから他のプロセッサ キャッシュにロードする必要があります。これによりピンポン状況になってデータ チャンクが連続的にプロセッサ コア間を往来するため、パフォーマンスが大幅に低下します。
Maya で提供されるプラグイン threadedBoundingBox には偽共のコストが図示され、回避方法が示されます。このプラグインでは、バウンディング ボックスの 1 つの要素の計算に複数のスレッドが使用されます。各スレッドは、ポイントのサブセットに対するバウンディング ボックスの X の最小値を表す float 値を計算します。算出された値は配列に書き込まれます。計算はさまざまな方法で実行され、シングル スレッド化されてからマルチスレッド化されて、出力結果の保持に使用される配列要素のスペーシングが変更されます。
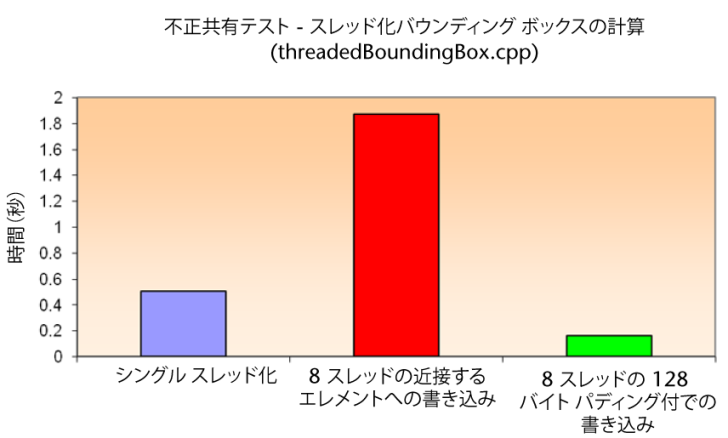
最初のテスト ケースでは、各スレッドは近接する配列要素に書き込みます。最大 8 個のコアで個別のスレッドを実行するマシンでは、各要素のサイズが 4 バイトしかないため、すべてのスレッドが同じキャッシュ ラインに書き込んで重大な偽共有がトリガされる可能性があります。このような場合、実際のパフォーマンスは非スレッド化実装よりも大幅に落ちます。
2 番目のテスト ケースでは、それぞれの値が常に個別のキャッシュ ラインに配置されるように、アクティブな配列要素間にパディングが追加されます。この場合、パフォーマンスは大幅に向上します。パディングを計算するには、最初に現在のプロセッサのキャッシュ ラインのサイズを照会します。Maya には、MThreadUtils::getCacheLineSize() という名前の新しい API メソッドがあり、ホスト プロセッサの実行時の正しい値を返します。このメソッドは、キャッシュ ライン アクセスに関してコードを適切に動作させるための最も安全な方法であり、将来的にプロセッサのキャッシュ ラインのサイズを拡大しても適切に動作します。
ハイパースレッディング
Core i7 (Nehalem)などのプロセッサにはハイパースレッディング機能が搭載されており、物理的に 1 つのコアを 2 つの論理コアとして処理し、2 つの実行スレッドを同じ物理コアで実行できる機能です。これによりパフォーマンスは向上しますが、各スレッドで多くのコア リソースを共有する必要があるため、2 つの物理コアと同等の効果は得られません。場合によっては、シングル スレッド化よりもパフォーマンスが低下する可能性もあります。
既定では、OpenMP や TBB などのスレッド化 API が論理コアごとに 1 つのスレッドを作成するため、ハイパースレッディングを活用できます。作成したコードでハイパースレッディングの影響をテストすることは重要です。パフォーマンスの低下が見られるため実行するスレッド数を論理プロセッサ数よりも少なくする場合、オペレーティング システムのスケジュール設定動作を確認する必要があります。Windows XP などの古いオペレーティング システムでは、ハイパースレッディングが有効なときに必ずしも最適な方法でタスクがスレッドにスケジュール設定されるわけではなく、1 つのコアがアイドル状態の場合に 2 つのスレッドがもう 1 つのコアで実行されることがあります。このような場合、システム BIOS でハイパースレッディングを無効にしてください。
 特に明記されている場合以外は、この作業は、Creative Commons 表示 - 非営利 - 継承 3.0 非移植ライセンス のもと認可を受けています。 Autodesk Creative Commons FAQ (英語版) を参照してください。
特に明記されている場合以外は、この作業は、Creative Commons 表示 - 非営利 - 継承 3.0 非移植ライセンス のもと認可を受けています。 Autodesk Creative Commons FAQ (英語版) を参照してください。