使用群集进行渲染
渲染 > 群集
切换与群集的连接。 使用群集渲染,通过在多台计算机之间共享渲染进程,可以加快渲染速度。从内部来看,“场景图形”通过网络传输到每台计算机,然后再拆分为分片进行渲染。结果将发送回主机以合成最终图像。
要配置群集,必须知道要用于创建群集的每台主机的 IP 地址或名称。每台主机上必须安装群集服务或 VRED Professional 版本。
为避免检出不需要的渲染节点许可,可以从群集服务中禁用单个主机。
头节点和渲染节点通过网络连接。配置将显示为一个树视图,其中包含全局选项、网络选项和每个渲染节点的选项。
如何配置群集
选择“渲染”>“群集”,以打开“群集”模块。
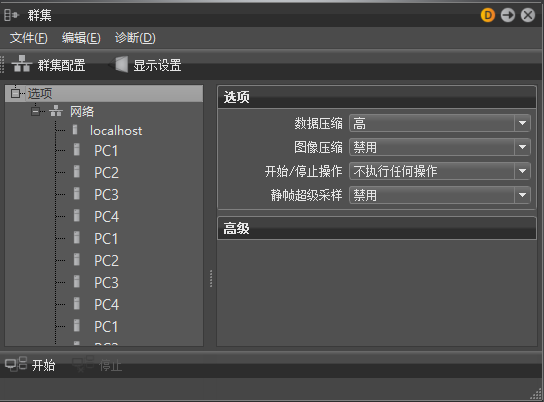
在左侧面板中,选择“选项”,然后选择“编辑”>“添加网络”。
执行以下操作之一:
要单独添加渲染节点,请选择“编辑”>“添加计算节点”,并在右侧面板中的“计算节点”下提供“名称”。
要一次添加多个节点,请选择“编辑”>“群集配置”以打开“群集配置”对话框。
在“配置”文本框中,添加配置。各种格式都可以识别,包括来自以前 VRED 版本中的群集模块的连接字符串。
PC1 PC2 PC3 PC4
PC1, PC2, PC3, PC4
PC1 - PC4
Master1 {PC1 PC2 PC3}
Master1 [forwards=PC1|PC2|PC3]
Master1 {C1PC01 - C1PC50} Master2 {C2PC00 - C2PC50}还可以从外部生成的文件读取配置。例如,启动脚本可以生成一个文件,其中包含所有可用群集节点的名称。如果“从文件读取配置”字段包含有效的文件名,则每次单击“开始”按钮时都会读取配置。
如果群集节点位于从运行 VRED 的主机无法访问的局域网中,则必须配置中间节点。 此节点必须连接到运行 VRED 的主机所在的同一个网络,并且通过另一个网卡连接到群集网络。在此设置中,必须配置两个网络。第一个是连接 VRED 与网关节点的网络。第二个是连接群集节点的网络。
在对话框的右侧面板中设置群集、网络和渲染节点选项。
要显示群集选项,请在左侧面板中选择“选项”。
要显示网络选项,请在左侧面板中选择“网络”节点。
若要显示渲染节点选项,请在左侧面板中选择节点。
如何导入旧版的群集配置
自 VRED 2016 SR1 起,光线跟踪群集配置已发生更改;自 VRED 2017 起,显示群集配置已发生更改。您可以导入旧配置,并将其转换为新格式。
在“群集”对话框中,选择“文件”>“导入旧版”。
如何将同一个群集节点使用多次
您可以从多个 VRED 实例连接到同一个群集节点。但是,这可能会导致问题,因为必须在多个 VREDClusterServer 实例之间共享可用资源。
例如,其中一个问题可能是由于不可预测的负载平衡结果或其他 VREDClusterServer 实例的 CPU 使用率导致的性能不良。当第二个用户尝试连接到同一个群集节点时,将出现以下消息:
一个或多个请求的群集节点上已经有一个 VREDClusterServer 正在运行。是否确实要启动群集并承担可能会出现性能问题的风险?
另一个问题是可用的内存。如果使用大型模型,则可能无法将多个模型加载到群集节点的内存中。VRED 尝试评估需要多少内存。如果请求的内存不可用,则会显示以下消息:
一个或多个请求的群集节点上已经有一个 VREDClusterServer 正在运行,可能没有足够的可用内存。是否确实要启动群集并承担服务器可能会不稳定的风险?
如果强制 VRED 启动群集服务器,则该服务器可能会发生不可预测的崩溃。
从群集服务禁用主机
您可以从群集渲染禁用单个主机。禁用的主机不检出渲染节点许可。
- 在菜单栏中,选择“渲染”>“渲染设置”以打开“渲染设置”对话框。
- 在“渲染设置”对话框中,向下滚动到“群集”部分,选择“启用群集”,然后输入主机名。
- 在主机之后添加
[RT=0]以将其禁用。
设置显示群集
在显示群集设置中,可以在通过网络连接的多个主机上查看场景。对于功能完备的显示群集设置,必须配置以下信息:
网络设置 - 必须在“群集”对话框中配置所有显示节点和用于光线跟踪加速的其他可选节点。
投影设置 - 必须定义在远程显示器上显示的内容。例如,显示器可以布置为平铺墙或 Cave。
显示设置 - 必须定义在哪个显示器上显示投影的哪个部分。可以定义视口的确切位置。被动设置或主动设置都是可选的。
在菜单栏中,选择“渲染”>“群集”以打开“群集”对话框。
设置显示节点和用于光线跟踪的任何其他节点。
单击“显示设置”以打开“显示配置”对话框。
设置投影。
支持多种投影类型。可以为平铺墙、Cave 或任意投影平面定义投影。可以为多个显示器定义多种投影类型。例如,VRED 可以处理平行于 Cave 投影的平铺显示。
投影类型(如平铺墙或 Cave)可为每一个显示器生成子投影。子投影是只读的。如果必须更改生成的投影以符合现实世界的情况,请在这些投影上单击鼠标右键并选择“转换为平面”以将其转换为平面投影。然后,可以分别编辑每个平面。
设置显示。
如果定义了投影,则每个投影必须映射到其中一个群集节点上的窗口。属于同一个显示器的所有窗口将组成一个显示节点。
使用快捷菜单可以复制并粘贴显示器、窗口和视口。例如,如果整个显示器由类似的窗口组成,这将简化定义。
启用硬件同步
VRED 支持在多个群集节点之间交换同步。必须安装、正确配置并连接同步硬件(例如 NVidia Quadro Sync)。如果所有这些前提条件都满足,则可以启用显示器属性的“硬件同步”属性。所有连接的显示器应该使缓冲区交换同步。
网络要求
要使帧速率和“场景图形”借以分发到群集中渲染节点的速度达到最高,网络硬件是一个限制因素。我们已采用不同的网络配置测量 32 节点群集的帧速率和数据传输速率。我们使用了一个非常简单的场景,利用 CPU 光栅化来生成图像,以确保渲染的速度不受 CPU 限制。所有测量都在专用网络中进行,该网络没有其他通信流量并且网络组件已配置好。
数据传输速率始终受群集中最慢的网络链接限制。理论上,Infiniband 的传输速率可高达 30 GB/s,但来自主机的 10 GBit 链路使其无法达到此速度。目前,我们还没有遇到通过 10 GB 以太网连接的大型群集。10 GB>Infiniband 配置已在多达 300 个节点中进行了测试。
| 网络 | 未压缩 (MB/s) | 中等 (MB/s) | 高 (MB/s) |
|---|---|---|---|
| 10 GB->Infiniband | 990 | 1100 | 910 |
| 10 GB->1 GB | 110 | 215 | 280 |
| 1 GB | 110 | 215 | 280 |
与“场景图形”的传输速率相比,帧速率在某些情况下不受最慢连接的限制。如果渲染节点连接到 1 GBit 交换机,并且该交换机具有到主机的 10 GBit 上行链路,则总共有 10 个渲染节点可以利用整个 10 GBit 上行链路。对于大型群集来说,网络延迟的影响变得更重要。Infiniband 应作为首选群集网络。
| 分辨率 | 网络 | 未压缩 (fps) | 无损 (fps) | 中等(有损)(fps) | 高(有损)(fps) |
|---|---|---|---|---|---|
| 1024x768 | 10 GB->Infiniband | 250 | 220 | 300 | 250 |
| 10 GB->1 GB | 250 | 220 | 300 | 250 | |
| 1 GB | 50 | 100 | 145 | 220 | |
| 1920x1080 | 10 GB->Infiniband | 130 | 120 | 200 | 130 |
| 10 GB->1 GB | 130 | 120 | 200 | 130 | |
| 1 GB | 20 | 40 | 50 | 130 | |
| 4096x2160 | 10 GB->Infiniband | 40 | 40 | 55 | 40 |
| 10 GB->1 GB | 40 | 40 | 55 | 40 | |
| 1 GB | 5 | 10 | 15 | 40 | |
| 8192x4320 | 10 GB->Infiniband | 10 | 12 | 14 | 13 |
| 10 GB->1 GB | 10 | 12 | 14 | 13 | |
| 1 GB | 1 | 2 | 3 | 10 |
我们已测试了 Mellanox 和 QLogic/Intel InfiniBand 卡。对于 10 GB 以太网,我们使用了 Intel X540-T1 网卡。
VRED 将尝试使用尽可能多的带宽。这可能会导致同一网络中的其他用户遇到问题。也就是说,在同一网络中传输大型文件将使渲染速度降低。如果可能,请尝试对群集使用专用网络基础设施。
启动群集服务
对于群集渲染,必须在渲染节点上启动渲染服务器。要自动执行此过程,请使用 VREDClusterService。此程序按需启动和停止群集服务器。
默认情况下,服务侦听端口 8889 的传入连接。一次只能为一个端口启动一个服务。如果要启动多个服务,则每个服务必须使用不同的端口。使用 -p 选项来指定端口。
要进行测试,可以手动启动 VREDClusterService。添加选项 -e -c 将在控制台上生成一些调试信息。
在 Windows 上,VRED 安装程序将添加系统服务“VRED Cluster Daemon”。此服务负责在系统启动时启动 VREDClusterService。从 Windows 控制面板选择“查看本地服务”,可以检查此服务。路径应指向正确的安装,启动类型应为“自动”并且服务状态应为“已启动”。
在 Linux 上,必须通过将 bin/vredClusterService 添加到 INIT 系统或手动运行 bin/clusterService 来启动该服务。
单击对话框底部的“启动群集”。
这将在 Windows 中启动 VREDClusterService。此服务将处理渲染,而不是 VRED 本身。
在主菜单中,选择“渲染”>“渲染设置”,然后输入要保存渲染的路径。
在“渲染设置”对话框中,单击“渲染”。
将打开“群集快照”对话框。它显示了渲染的预览及其进度。
在渲染过程中,随时选择“群集快照”对话框中的“更新预览”即可更新预览图像。
可以随时单击“取消并保存”中止渲染,并将其当前状态保存到文件中,或者一直等到渲染完成,然后单击“保存”。
从群集服务禁用主机
您可以从群集服务禁用单个主机。排除的主机不检出渲染节点许可。
- 在主菜单中,选择“渲染”>“渲染设置”以打开“渲染设置”对话框。
- 在“渲染设置”对话框中,滚动到“群集”部分,然后选择“启用群集”。
- 输入主机名,并在要禁用的主机之后添加
[RT=0]。
Linux 上的 VRED 群集
提取 Linux 安装
Linux VREDCluster 安装程序作为自解压二进制文件提供。该软件包的文件名包含版本号和创建日期。要能够将内容提取到当前目录,请将安装程序作为 shell 命令运行。
sh VREDCluster-2016-SP4-8.04-Linux64-Build20150930.sh
这会创建目录 VREDCluster-8.04,其中包含群集渲染所需的所有文件。每个群集节点必须对此目录具有读取权限。它可以单独安装在每个节点上或共享网络驱动器上。
要能够连接一个群集节点,必须启动群集服务。这可以通过手动调用以下命令或将脚本添加到 Linux 启动进程来完成。
VREDCluster-8.04/bin/clusterService在 Linux 启动时自动启动 VRED 群集服务
在 Linux 上,可以使用多种方法在启动系统时启动程序。每个 Linux 发行版的方法略有不同。一种可能的解决方案是,将启动命令添加到 /etc/rc.local。此脚本在每次启动时以及运行级别更改时执行。
例如,如果安装文件存储在 /opt/VREDCluster-8.04 中,则应按如下方式编辑 rc.local:
#!/bin/sh -e
killall -9 VREDClusterService
/opt/VREDCluster-8.04/bin/clusterService &
exit 0例如,如果不希望以 root 身份运行服务,则可以 vreduser 身份启动服务。
#!/bin/sh -e
killall -9 VREDClusterService
su - vreduser '/opt/VREDCluster-8.04/bin/clusterService &'
exit 0在系统启动时启动 VRED 服务的另一个选项是将 init 脚本添加到 /etc/init.d。将 init 脚本从安装目录 bin/vredClusterService 复制到 /etc/init.d。然后,您必须为不同的运行级别激活该脚本。
在 Redhat 或 CentOS Linux 上使用:chkconfig vredClusterService on
在 Ubuntu 上使用 update-rc.d vredClusterService 默认值
连接许可服务器
许可服务器的地址必须存储在主目录 .flexlmrc 下的配置文件中,或者可以设置为环境变量 ADSKFLEX_LICENSE_FILE。如果服务器名为 mylicenseserver:
~/ .flexlmrc 应包含:ADSKFLEX_LICENSE_FILE=@ mylicenseserver
或添加到您的登录脚本:export ADSKFLEX_LICENSE_FILE=@ mylicenseserver
确保为启动群集服务的用户设置环境。
访问日志信息
日志文件将写入目录 /tmp/clusterServer/log。应使用 Web 浏览器查看日志文件。要进行故障排除,在控制台模式下启动群集服务可能会有帮助。停止正在运行的群集服务,并手动启动 bin/clusterService -e -c。现在,所有调试和错误消息都写入控制台。
有用的命令
检查该服务是否正在运行:ps -C VREDClusterService
停止群集服务:killall -9 VREDClusterService
停止群集服务器:killall -9 VREDClusterServer
完全无阻塞网络/阻塞网络
完全无阻塞网络允许所有连接的节点使用全部链接速度彼此通信。对于 16 端口的千兆位交换机来说,这意味着交换机能够处理 16 个端口并行读取和写入的通信流量。这需要 32 GB/s 的内部带宽。VRED 在使用无阻塞网络时将发挥最佳性能。例如,“场景图形”的传输通过将数据包从节点发送到节点来完成,类似于管线。这远远快于将整个场景直接发送到每个节点。
如果可能,请不要使用网络集线器。集线器会将传入的数据包发送至所有连接的节点。这将导致“场景图形”传输变得非常缓慢。
对于大型群集,使用完全无阻塞网络可能非常昂贵。如果群集节点连接到多个交换机,则只需按渲染节点所连接的交换机对渲染节点进行排序即可获得良好的性能。
例如,如果您有一个具有 256 个节点的群集,这些节点连接到 4 个交换机。最坏的配置将是:
Node001 Node177 Node002 Node200 Node090 ...
通过排序列表可以实现更好的结果:
Node001 - Node256
如果此配置导致出现任何性能问题,请尝试参照您的网络拓扑进行配置:
Node001 { Node002 - Node064 }
Node065 { Node066 - Node128 }
Node129 { Node130 - Node192 }
Node193 { Node194 - Node256 }使用此配置可有效减少交换机之间传输的数据量。
疑难解答
无法连接渲染节点
- 使用 ping 主机名检查节点是否可连接。
- 尝试使用 IP 地址,而不是主机名。
- 必须允许端口 8889 通过防火墙。
- 必须在渲染节点上启动 VREDClusterService。尝试通过 Web 浏览器使用 http://hostname:8889 连接。
无法使用 InfiniBand 连接群集服务器
- 仅 Linux 支持通过没有 IP 层的 InfiniBand 通信。
- 必须正确配置 Infiniband 网络。使用 ibstat 检查您的网络状态或使用
ib_write_bw检查两个节点之间的通信。 - 检查
ulimit -l。锁定的内存量应设置为无限制。 - 检查
ulimit -n。打开文件的数量应设置为无限制或设置为较大的值。 - 如果无法通过
Infiniband运行VREDClusterServer,则在大多数情况下可以使用IPoverInfiniband,而且性能损失很小。
但是,偶而会因较高的帧速率而挂起
- 也许是因为网络被其他应用程序占用。
- 尝试将网络速度更改为“自动”。
- 尝试降低图像压缩或将图像压缩设置为“禁用”。
帧速率不如预期的高
- 如果 CPU 使用率较高,渲染速度将受 CPU 限制。可以通过降低图像质量来提高帧速率。
- 如果 CPU 使用率较低,而网络使用率较高,则启用压缩可以提供更高的帧速率。
- 包含非常复杂材质属性的小屏幕区域可能会导致渲染节点之间的负载平衡非常差。结果会导致 CPU 使用率和网络使用率都比较低。在这种情况下,唯一的选项是找到这些热点,并降低材质质量。
为什么网络使用率低于 100%
如果渲染速度受 CPU 限制,则网络使用率将始终低于 100%。在这种情况下,提供更快的网络将不会提供更高的帧速率。
尝试使用 iperf 等工具检查可达到的网络吞吐量。 对于 10 GB 以太网,VRED 使用多个通道来加快通信速度。这可以使用
iperf -P4模拟。检查双向吞吐量。网络速度不但受使用的网卡限制,而且受网络交换机和集线器限制。如果网络被许多人员使用,则吞吐量在不同时间变化非常大。
测试表明,在 Windows 中很难 100% 利用 10 GB 以太网卡。在不进行优化的情况下,只能达到 50%。可以尝试使用测量工具并调整网卡的性能参数。如果渲染速度确实受网络限制,则应将图像压缩设置为“无损”或更高。
对于 Intel 10 GB X540-T1 以太网卡,以下选项可以在 Windows 上提高网络吞吐量:
- 接收侧缩放队列:
Default = 2,更改为4 - 性能选项/接收缓冲区:
Default = 512,更改为2048 - 性能选项/传输缓冲区:
Default = 512,更改为2048 - 有时,将网卡安装到另一个 PCI 插槽可以提高网络吞吐量。
- 接收侧缩放队列:
在 Linux 上,您可以在
/etc/sysctl.conf中增加参数net.ipv4.tcp_rmem、net.ipv4.tcp_wmem、net.ipv4.tcp_mem。
为什么 CPU 使用率低于 100%
- 如果渲染速度受网络限制,CPU 使用率将达不到 100%。
- 要在多个渲染节点之间分配工作,屏幕将拆分为分片。然后每个节点渲染其中的多个分片。在大多数情况下,不可能为每个节点分配完全相同的工作量。根据场景,这可能导致 CPU 使用率较低。
Windows 中的 Mellanox Infiniband
借助面向 Windows 的 Mellanox
MLNX_VPI_WinOFinfiniband 驱动程序,可以使用 TCP over Infiniband 连接群集节点。网络设置如下所示:- 网络:已选择
- 网络类型:以太网
- 网络速度:40 GB
- 加密:未选择
如果 Linux 配置为使用“已连接模式”,则无法连接到 Linux 网络。请确保所有连接的节点上的 MTU 相等。