SQL を使用して、より複雑な検証ルールを独自に作成することができます。
当該サンプル ネットワークでは、ポンプ場オブジェクトを別のポンプ場オブジェクトに直接接続することは無効です。この一連の SQL クエリーでは、ユーザー定義フィールド user_number_2 を使用してポンプ場への接続をカウントします。最後に、別のポンプ場に直接接続されているポンプ場が選択されます。
| ステップ | ステップの説明 | クエリー | イメージの例 |
|---|---|---|---|
|
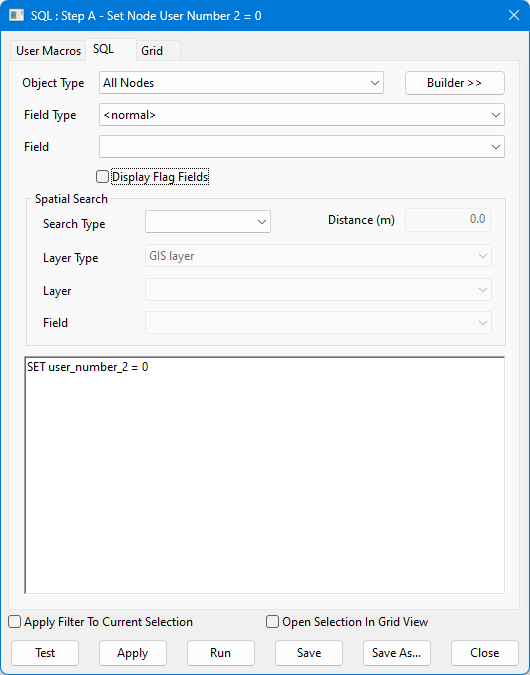
A |
まず、すべてのノードのユーザー フィールド値をゼロに設定します。 重要: これを行う前に、使用するフィールドに有用な情報が含まれていないことを確認してください。
|
SQL query context:
SET user_number_2 = 0 |
|
|
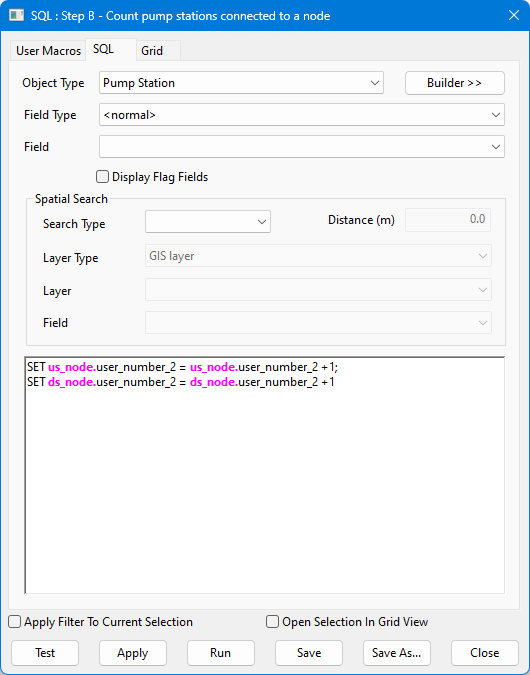
B |
次に、各接続のユーザー ナンバー フィールドの番号を増分して、ポンプ場オブジェクトへのすべての接続をカウントします。このクエリーの[オブジェクト タイプ]フィールドが[ポンプ場]に設定されていることに注目してください。
|
SQL query context:
SET us_node.user_number_2 = us_node.user_number_2 + 1; SET ds_node.user_number_2 = ds_node.user_number_2 + 1 |
|
|
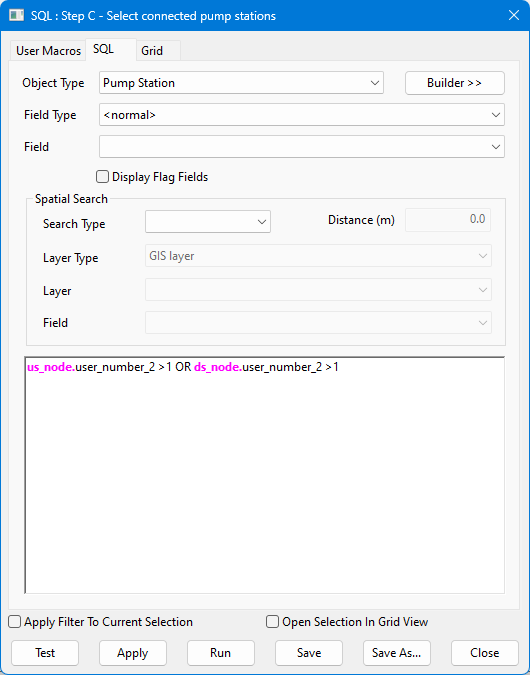
C |
次に、他のポンプ場に接続されているすべてのポンプ場を見つけます。これらが選択されます。 |
SQL query context:
us_node.user_number_2 > 1 OR ds_node.user_number_2 > 1 |
|
|
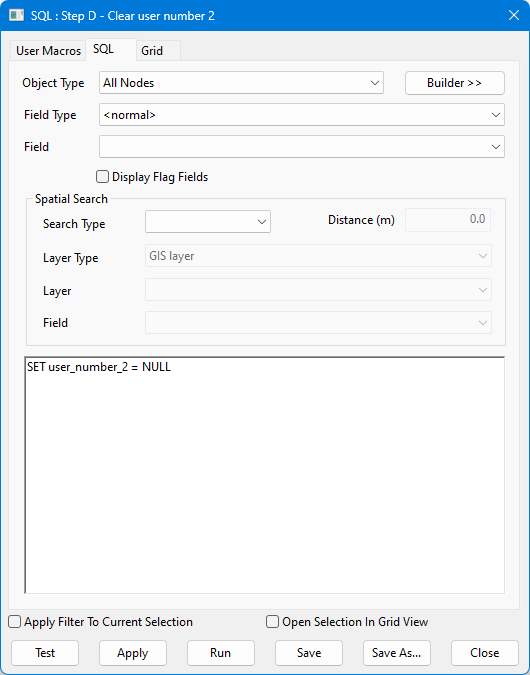
D |
最後に、[ユーザー ナンバー 2]フィールドからカウントを削除します。これはもう必要ないためです。 |
SQL query context:
SET user_number_2 = NULL |
|
|
E |
この検証プロセスを構成する SQL クエリーは、[保管クエリー グループ]に配置することができます。その後、[保管クエリー グループ]のオブジェクトを[ジオプラン]にドラッグ アンド ドロップすることで、ネットワーク上のグループ内のすべてのクエリーを実行できます。クエリーはアルファベット順に実行されるため、名前を付けるときに注意してください。 |
|
|