Threading and Maya
Maya API threading interface, description and examples
Having laid the groundwork by describing required threading functionality, this section discusses the functionality provided by the Maya API, and illustrates usage with some example plug-ins supplied with Maya.
In Maya, a number of threading classes exist to provide support for thread creation, management and locking. These threading classes build on Intel's TBB threads, which are used internally by Maya. The classes expose a native threading-like API to plug-in writers. Note that these classes do not require the plug-in writer to use TBB directly in their plug-ins, or even be familiar with TBB. Since these threads are actual internal Maya threads, they respect thread count settings applied in Maya, and avoid the problem of creating increasing numbers of active threads as plug-ins are themselves threaded. They also provide protection from oversubscription problems in some cases due to the way TBB implements threading.
The API provides the following three major areas of functionality:
- fork-join threading implementation model
- asynchronous task-based threading model
- threading synchronization interfaces
The architecture employs object reference counting to assist with memory management and to delay deallocation of objects until all users of the object are finished with it. A successful call to an API function returns an interface pointer, and the caller is responsible for calling release() on that interface when they are finished with it. Failure to do so could lead to memory leaks.
The return MStatus of calls should always be checked, as it should never be assumed that a call will always succeed.
Thread creation and management using the Maya API
MThreadPool
This class creates or reuses a thread pool. Since creation and deletion of threads is expensive, it is a good idea to make use of the thread pool where possible, and try to keep it around between invocations of the plug-in rather than recreate it each call. The thread pool is reference counted, so it is possible to create it in the initialize() method of the plug-in and keep it for the duration of the application, releasing it in the uninitialize() method. It provides methods common to native threading implementations, allowing for migration of plug-ins from native threads over to this API.
The implementation requires the creation of a fork-join context which takes a function pointer as an argument. This function needs to implement the decomposition of the given problem into smaller chunks (tasks) which are then mapped to threads by TBB internally.
Note that the use of TBB internally means that it is possible to nest threaded fork-join regions created with MThreadPool without causing oversubscription, as TBB will schedule all the tasks in parallel by mapping them to cores.
Example
See the example plug-in threadTestCmd, supplied with Maya, which computes prime numbers using a thread pool. This requires the creation of a new function, DecomposePrimes, to decompose the problem into smaller parts. The code within DecomposePrimes looks very similar to a native threading implementation, the main difference being the use of the control variable NUM_TASKS rather than the number of threads. As discussed above, TBB internally takes care of mapping the tasks to threads, and ensures optimal load balancing.
MThreadAsync
The MThreadAsync class provides methods common to native threads that allow the user to map independent asynchronous tasks to threads. The current implementation does not use a thread pool for this interface but instead creates new threads for each asynchronous task. This means it is possible to cause oversubscription, so care must be taken in managing the number of asynchronous threads and the amount of work they do concurrently.
The createTask() method takes a function pointer that executes the asynchronous task and also a pointer to a callback function that can be used by developers to implement a fork-join or any other signaling mechanism.
Example
Refer to the example plug-in threadTestWithLocksCmd.cpp. This plug-in is shipped with Maya. Compared with the thread pool example described previously, this implementation does not require the creation of a separate function like DecomposePrimes, as it mimics the native threading API closely. However the asynchronous threading interface does not provide a join method. The example shows how the equivalent functionality may be implemented by implementing barriers in the callback functions (WaitForAsyncThreads.)
The function Maya_InterlockedCompare() could be implemented more efficiently using the atomic compareAndSwap() method in the MAtomic.h header provided with the Maya API.
Locking operations using the Maya API
System locks
MMutexLock and MSpinLock are system locks. MMutexLock uses pthread_mutex_lock on OSX and Linux, and EnterCriticalSection on Windows. The difference between these is that a mutex lock is a heavier operation but requires no CPU resources once the lock is held. A spin lock is a light operation, but requires heavy CPU resources while waiting. So if the wait is likely to be short, use a spin lock. These classes release the lock in their destructor, meaning explicit release is not required, and the lock will be safely released even if an exception is thrown in the locked code.
It is best to use different instances of lock objects for unrelated code. If a single lock object is used in many different places, threads may be blocked even if working on unrelated tasks.
Atomic operations
The Maya API includes an implementation of atomic operations in the API header called MAtomic.h which provides cross-platform atomic operation functionality. Below is a listing of the atomic operations available. Full descriptions are given in the file itself and in the Maya API class documentation.
Performance of locking and atomic operations
The following are the performance numbers for the cost of spin and mutex locks and atomic operations on Windows 64. (Other platforms are similar with the exception of OSX that mutex is much slower.) The plug-in to generate these numbers is called threadingLockTests, and is shipped with Maya as a sample plug-in for you to test performance on your own system. It requires a compiler that supports OpenMP. Note that this plug-in is an extreme case as the code does very little actual parallel work within the locked region. However it does give an indication of the relative cost of these locks under heavy contention. (A contended lock is one where another thread attempts to gain the lock that is already held by one thread. Having more running threads increases the chances of lock contention dramatically. Performance suffers significantly if there is high contention.)
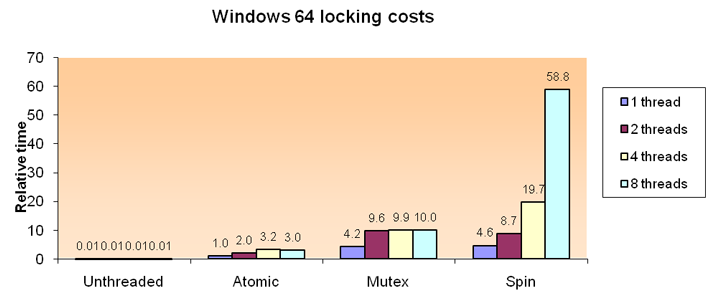
Note the benefit of atomic operations over the various mutex locks. Also note that code without any locking is far faster than even the atomic implementation. Clearly it is best to avoid locks wherever possible. If not, atomic operations should be used, and only if this is not possible should full mutex or spin locks be used.
Lock granularity is a large complex topic in itself. In general it is best to lock at a finer grained level rather than a coarser level, as it allows more opportunities for parallelism. However too much fine grained locking can eat up a lot of system time and add significant complexity to the code. The challenge is to find an optimal balance point between coarse and fine grained locking. Since coarse grained locking is easiest, it is best to start with such locking and then more to progressively finer grained locking until performance stops improving.
The worst locking problems are those that prevent the application from progressing at all:
- Deadlocks occur when two threads each take a different lock, then each attempts to acquire the lock held by the other thread. No further progress is possible and the application hangs.
- Livelocks are similar to deadlocks except that each thread continually remains active without progressing past the lock. An example would be code that can detect a deadlock and roll back from it, but then simply allows the same evaluation to recur, leading to an infinitely repeating cycle.
Maya API threading example - deformer
The plug-in splatDeformer supplied with Maya is an example of a threaded deformer implementation. This example uses OpenMP rather than the Maya native API, since the focus here is on the approach taken to threading a deformer rather than the threading implementation itself, and OpenMP requires the least amount of additional code to implement threading.
The deformer is somewhat similar to a Maya sculpt deformer. A deforming mesh can be used to modify a selected mesh. The algorithm applies a deformation to every point on the mesh by snapping it to the closest point on the deforming object. The closest point operation is computationally intensive, and therefore is a good candidate for threading, unlike some simpler deformers where threading overhead is likely to outweigh any potential benefit.
Here are some items of note in this implementation:
- Note that all DG access is performed outside the threaded region. This is because DG access is generally not threadsafe, although there are exceptions (see section Threadsafe Maya API methods and classes below.)
- All the elements are read into arrays using MItGeometry rather than using the iterator to do the loop traversal. This again ensures we avoid DG access in threads, and also avoids the problem that it is difficult to thread an iterator (although it can be done with Intel's OpenMP taskq extension.)
- There are fast methods on MItGeometry that read and write all points in a single function call, allPositions() and setAllPositions(). These are much more efficient than querying and setting the points one by one. If you are working directly with points on an MFnMesh in Maya there are new methods getRawPoints() and getRawNormals() which are even faster as they return a const pointer directly to the internal data. Do not be tempted to cast away the const and modify the data in place via this pointer, as this will almost certainly lead to data corruption.
- The closest point methods on MFnMesh are not threadsafe, and are also relatively inefficient for multiple evaluations of a fixed mesh. The class MMeshIntersector uses a cached tree traversal so is much faster, and is also threadsafe. The intersector is set up and initialized outside the loop, then evaluated inside the loop to get the full parallelism benefit.
- The meshPoint object must be allocated inside the loop so it is created on the current thread's stack. Allocating the object outside the loop would cause race conditions. Inadvertently writing to variables that were declared outside the loop is a common problem when trying to add threading to code that was not initially threaded, and great care must be taken to track all such variables down. It is good practice to declare variables in as local a scope as possible and avoid the practice of declaring variables at the top of a function anyway, and the fact that it makes any potential threading work easier in future is an additional benefit. It is also worth declaring any variables before the loop as const where possible, so write access to these variables from within the loop can be caught at compile time.
- The values are read from a shared array and written into a shared array so there is some risk of cache misses on reads and false sharing on writes. However the default OpenMP traversal scheme for a loop like this would be to have the first thread evaluate the first (nPoints/nThreads) elements and other threads evaluate equal sized contiguous chunks. This access pattern minimizes both cache misses and false sharing.
- If one of the closest point operations fails, the evaluator does not immediately abort, but instead sets a bad status flag and skips remaining iterations. In this specific case it is because OpenMP does not permit break calls from inside a threaded region. However it is often the easiest approach in general, compared with attempting to abort other threads that are in mid-evaluation.
- After the threaded region, the iterator is used to write the values back into the output object.
Scalability is limited by the serial portion of the code. For this reason it is important to optimize the code outside the threaded region. So for example it is best to get and set data in as large chunks as possible from the DG. This minimizes DG overhead. Several methods were added to MFnMesh to allow the user to retrieve all components of various types in a single operation, specifically for this purpose. The danger of course is increased memory usage, as these arrays must be maintained for the duration of the compute method compared with the iterator approach that updates one element at a time in place. The method MFnMesh::getRawPoints provides maximum speed and avoids memory overhead by returning a pointer directly to the internal data.
Some deformers cache their weights in the datablock. Reading from the datablock is slow and potentially not threadsafe. Often deformer weights do not change from frame to frame anyway, so in such cases it is best to read the weights once and store them in local arrays within the deformer class, then do the threaded deformer evaluation using those cached weight values.
Initializing singleton objects in Maya plug-ins
A common coding pattern is creation of a singleton object, perhaps initializing global data for a solver. Usually this is a very simple operation:
static solver* singleton = 0
if (singleton == 0) {
singleton = new Solver();
}
However when it comes to threaded code it becomes a very challenging problem, and entire papers have been written on the best approach to implementing this pattern, the problem being that optimizers often reorder code to break apparently threadsafe implementations. An obvious solution is to use a lock, but that is a heavyweight operation that is only really required on first construction.
In general, if the overhead of the initialization is not too large, it is best to put it into the initialize() method of the plug-in, which can be guaranteed to run serially.
If the object is large or expensive to construct, or the plug-in is not always executed, it is preferable to use lazy evaluation and initialize the object only when required. If this is the case, here is an implementation that may be helpful. It makes use of the MAtomic API class supplied with Maya:
static Solver* singleton = 0
if (singleton == 0) {
Solver* solver = new Solver();
if(!MAtomic::compareAndSwap(&singleton, 0, solver)) {
delete solver;
}
}
On invocation, multiple threads enter the if condition and potentially create multiple solvers at the same time. The first thread to reach the compareAndSwap sets the solverSingleton pointer to the address of the new solver, and all subsequent threads delete their solver instances once they finish creating them. Although this seems disturbingly wasteful at first glance, it is actually very efficient, because the performance hit is taken just once on startup, but all subsequent calls to the code just do a simple pointer compare, with no locking at all required.
If it is unsafe to have multiple threads in the Solver constructor, here is an alternative template to start from:
static Solver* singleton = 0 static int doneInit=0; if(MAtomic::compareAndSwap(&doneInit, 0, 1)) { singleton = new Solver(); doneInit = 2; } while(doneInit != 2) {}; // spin-wait
This code ensures the solver is only initialized once. To prevent other threads from accessing the object after the constructor has initialized the solver pointer but before it has finished its work, a spin-wait loop is applied that is not exited until the object has been fully initialized. The downside is that this approach requires an atomic operation and at least one traversal of the while loop for every subsequent call. There is also some concern about the compiler reordering the doneInit=2 line to above the constructor, so an additional lock around the solver constructor call may be required to ensure this is avoided.
This is a good illustration of how even simple tasks can become tricky in a threaded environment.
Threadsafe Maya API methods and classes
The Maya API is very extensive, and it is not possible at this point to document every function and class to indicate whether it is threadsafe. This section focuses on some of the key classes that users are likely to want to call from threaded code.
Unfortunately it is not safe to make any assumptions about which methods may be threadsafe. Unless the function is inline and can be checked directly, there is always the risk that code may not be threadsafe. Even query methods may occasionally be unsafe as their classes may store internal state that is modified by the query.
Some classes rely on lazy evaluation so certain methods must be "primed" by calling them once outside a threaded region to update the internal data structure. For example, MFnMesh::getVertexNormal will first check to ensure the normals are up to date, and if they are not, it will recompute them. Thus two simultaneous calls to this function when the normals are not up to date will be unsafe. However once one call has been made and the internal data structures are updated, subsequent calls are threadsafe as long as the object has not been modified since the initial priming call.
Threadsafe classes
- MPoint/MFloatPoint/MVector/MFloatVector/MMatrix
- All read-only methods, no write methods.
- M*Array container classes
Array classes are safe for read access. For writes, the set() methods are safe as they do not resize the array. However append(), insert(), remove() are not safe as they potentially resize the array.
- MFnMesh
- closestPoint/intersection methods are NOT threadsafe.
- get* and numNormals methods are safe once they have been primed.
- getRawPoints/getRawNormals are threadsafe.
- MMeshIntersector is threadsafe.
- MDataHandle - methods can not in general be assumed to be threadsafe.
- asXXX() calls are safe since they just return pointers to the data referenced by the handle without worrying about whether they are clean or not (which is also the least common thing to do when reading data).
- asGenericXXX() calls are not safe since they use the read/write reference counting to get at Tdata information.
The context is important too - if you just have a bunch of MDataHandle objects lying around then you have already done the thread-unsafe part of extracting them from the datablock. The first level of danger is that the datablocks may not exist at all yet since they are lazily created so you have to make sure only one thread does that. The second level is when you are getting handles for the purpose of reading data the datablock may trigger an evaluation (if you use the inputValue(...) methods) which has its own thread safety issues.
The safest algorithm for doing a compute would be:
- Get all input MDataHandles.
- PARALLEL( Get all input values from unique handles )
- Perform the computation (in parallel if possible)
- PARALLEL( Put all output values into handles )
- PARALLEL( Get any output values of interest, in any order, not necessarily unique)
- MArrayDataHandle
This class maintains internal state since it is effectively a smart pointer into the datablock, so there are obvious dangers in using the same handle in multiple threads. Multiple threads making calls in parallel to jumpToElement() followed by query calls will not be threadsafe.
Non-threadsafe functionality
- MFnNurbsCurve evaluation, for example, point on curve computation
- MFnNurbsSurface evaluation, for example, point on surface computation
- MFnSubd evaluation
 Except where otherwise noted, this work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. Please see the Autodesk Creative Commons FAQ for more information.
Except where otherwise noted, this work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. Please see the Autodesk Creative Commons FAQ for more information.