Rendering Framework
To understand how the plug-in interface interacts with Maya, a frame of reference needs to be provided. This section outlines the rendering framework of the current hardware renderer. It also points out the differences and similarities between the “old” and “new” rendering logic.
There is now a clear separation of responsibilities and an underlying hardware rendering framework exists. In the old system rendering was mainly the responsibility of DAG objects, and now it is the responsibility of a renderer.
First, there is a distinction between data which is used to represent Maya constructs and data which is used for rendering. While Maya manages DAG objects, the rendering framework maintains a separate database which tracks instances of Maya DAG objects. This database is composed of constructs that we call renderable objects. For the most part in general there is a 1:1 relation between renderable objects and DAG instances.
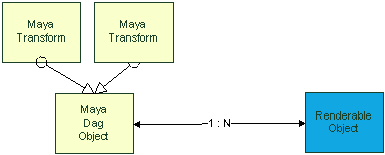
Figure 1: An example set of DAG objects in a hierarchy shown on the left. The result could be 2 renderable objects for the 2 Maya DAG object instances.
Synchronization between Maya constructs and the rendering database is facilitated by a “dirtying” or change management mechanism which tracks all appropriate changes per node or DAG object. This differs from the previous mechanism which required changes to be broadcast to an arbitrary set of clients.
Unlike the old model, data update is not driven by synchronization. In fact updates can no longer cause synchronization to occur as this would result in recursive updates. Synchronization is always actively executing, while update is performed on-demand when a render is required. In the new framework, a rendering request can be invoked non-interactively via the command line or via the pre-existing idle refresh mechanism used for interactive (viewport) rendering. One main difference to note is that non-interactive requests are always satisfied while interactive requests may or may not be satisfied depending on whether the refresh is executed.
To satisfy a rendering request some kind of render loop logic needs to be performed. This render loop can be visualized as a pipeline with various “phases.” For simplicity we start with these familiar phases:
- Object level pruning of “renderable objects” (e.g. based on visibility)
- Updating of data (Update Phase)
- Sending down “renderables”
- Drawing “renderables”
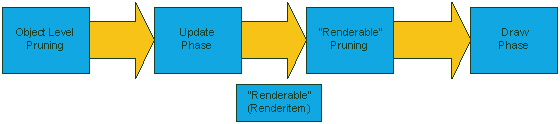
Figure 2: Renderables objects are fed in as input and pruned as required. Those that are not pruned will perform synchronization and update as required and produce renderables. These renderables may undergo further pruning before being sent to render.
The Update Phase is responsible for synchronization and for determining what is “renderable.” We call such renderable objects Render Items. Render items are passed down the pipeline and additional logic is then applied to filter or prune out what should actually draw (“Renderable Pruning”). At the tail-end of the pipeline is the Draw Phase which actually performs rendering.
Note that a Render Item is left vague for the moment. For now, it is sufficient to know that it represents an atomic unit containing both the render data and the render algorithm. Each unique algorithm and each unique geometric primitive generally results in a unique renderable. As an example, an algorithm to draw control points would require one renderable, while one to draw filled triangles with bump mapping would require another. In this example both the data primitive and the algorithm varies.
By contrast to the new organization, the old system looks like this:
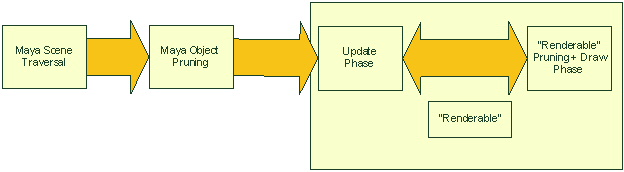
Figure 3: Without a database, a scene traversal is required. The object is responsible for all tasks required to update and draw.
Without a separate database, a full scan of Maya constructs in a scene is performed. After initial object pruning, each object is free to draw itself. As there is no clear separation between update and draw, this results in the ability to perform interleaved evaluation, translation and draw in one “phase.” As there is no renderer, little cross-object optimization can be performed. These are all undesirable properties and are discouraged or disallowed in the new framework.
We consider the new system of update as a pull model where data is updated on demand and only if required. If nothing changes between renders then the pipeline can run without interaction with the Maya scene. The old model is seen as more of a push model where for every render we rescan the entire scene and try to update everything so it can be examined later on for relevance.
 Except where otherwise noted, this work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. Please see the Autodesk Creative Commons FAQ for more information.
Except where otherwise noted, this work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. Please see the Autodesk Creative Commons FAQ for more information.