
次の例は、グラフの色とカテゴリに基づいてプロファイルを解釈する方法、および Maya の各パフォーマンスの最適化がシーンのパフォーマンスに与える影響を示しています。次の例はすべて、Maya 2019 の同じ単純な FK キャラクタの再生から生成されたものです。
DG の評価
- ダーティな伝播カテゴリのピンクと紫のダーティな伝播イベント。
- 評価カテゴリの濃い緑色のプル評価イベント。
- VP2 評価カテゴリの青色の VP2 プル変換と水色の VP2 レンダリング。
- VP2 評価カテゴリの黄色のイベントは、VP2 が ディペンデンシー グラフ ノードからのデータの待機に消費した時間を示します。
この例では、各フレームのかなりの部分がダーティー伝搬に消費されています。これは評価マネージャで対応できる問題です。
EM 並列評価
- FK リグの EM 並列評価イベントの色が桃色、褐色、茶色で表示されています。大量のイベントは、いくつかの評価が並行して実行されていることを示しています。
- 黄褐色および茶色の EM 並列評価イベントは、Maya が変形したメッシュを計算するためにスキン クラスタを評価するときに発生します。ディペンデンシー グラフには並列性がないため、これらのイベントは順次発生します。
- 濃い青色と青色の VP2 直接更新イベントは、データを VP2 のレンダリング可能な形式に変換します。
- メイン カテゴリの黄色と VP2 評価カテゴリの水色は VP2 レンダリング イベントです。
この例では、Vp2SceneRender (4) に消費される時間ははるかに少なくなります。これは、ディペンデンシー ノードからのデータの読み取りに消費された時間がレンダリングから EM 並列評価(1 と 2)に移動したために発生します。DG 評価ではデータ プル モデルを使用し、EM評価ではデータ プッシュ モデルを使用します。さらに、ジオメトリ変換(3)もレンダリングから評価に移動しました。評価中のジオメトリ変換を「VP2 直接更新」と呼びます。
各フレームの大部分はジオメトリ データの変形と変換に消費されます。これは GPU オーバーライドで対応できる問題です。「評価マネージャのパフォーマンスを高める」の「GPU オーバーライド」を参照してください。
GPU オーバーライドによる EM 並列評価
- 明るい黄色と暗い黄色の GPU オーバーライド イベントは、EM 並列評価プロファイルの長いシリアルの中央部分(EM 並列評価の 2 と 3)を置き換えました。これらの GPU オーバーライド イベントは、CPU がデータを整列化して GPU 計算を開始するのにかかる時間を表します。
- ここでは、GPU オーバーライドを使用したリグ評価イベントの相対サイズが大きくても、桃色、褐色、茶色の EM 並列評価イベントの時間は EM 並列評価とほぼ同じです。このサイズの違いは、このプロファイルのスケールが以前のプロファイルのスケールと異なる(5 ミリ秒対 12 ミリ秒)ためです。
- 水色の VP2 レンダリング イベントでは、同様の相対ストレッチ(2)が発生しています。
EM 評価のキャッシュされた再生
- 黄色のキャッシュ リストア イベントは、各 FK リグ ノードを更新してデータをキャッシュするのにかかる時間を記録します。データの VP2 リプリゼンテーションの更新を追跡する茶色の VP2 直接更新イベントもあります。
- 変形したメッシュの黄色のキャッシュ リストア イベント。これは、データを Maya ノードにリストアし、VP2 直接更新を使用して描画するためにデータを VP2 に変換するのにかかる時間を表します。
EM VP2 ハードウェア のキャッシュされた再生
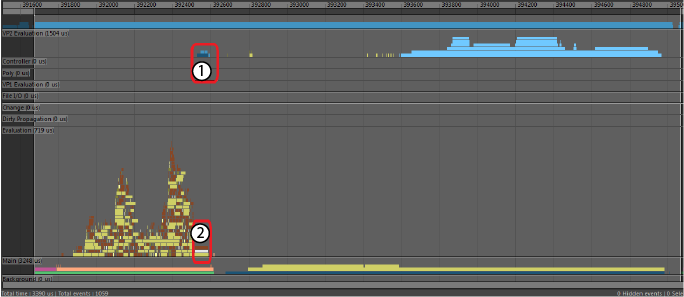
- 濃い青色の VP2 ハードウェア キャッシュ復元イベントは、長いシリアルのキャッシュ復元イベント(上のセクションの EM 評価のキャッシュされた再生の #2)を置き換えます。データはすでにレンダリング可能な形式で GPU に保存されているため、VP2 ハードウェア キャッシュの復元は非常に高速です。
- 灰色のキャッシュのスキップ イベントは、ディペンデンシー ノード内のデータが更新されていないことを示しています。
評価にバインドされたパフォーマンス
シーンの主なボトルネックが評価にある場合、シーンは「評価にバインドされた」と見なされます。いくつかの問題によって評価にバインドされたパフォーマンスが生じる可能性があります。
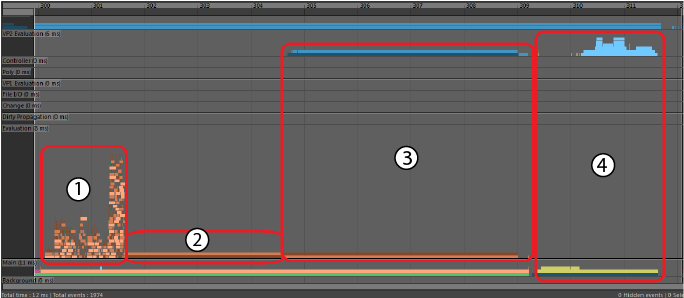
- ロック競合
- 多くのスレッドが共有リソースにアクセスしようとすると、ロック管理のオーバーヘッドが原因でロックの競合が発生します。評価にほぼ同じ時間がかかる場合は、どの評価モードを使用しても、この発生を識別できます。他のスレッドが共有リソースの使用を終了するまでスレッドが進行できないと、ロックの競合が発生します。
-
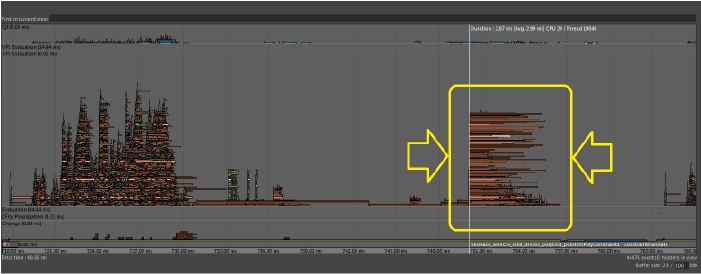
- 上の画像は、異なるスレッドでほぼ同時に開始され、それぞれが異なる時点で終了する多くの同一タスクを示しています。このタイプのプロファイルは、多くのスレッドが同時にアクセスする必要がある共有リソースがある可能性を示しています。
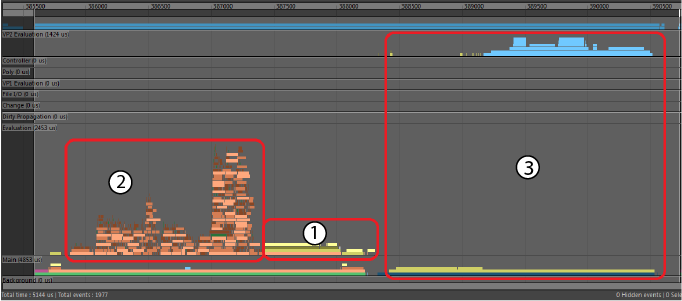
- 以下は、同様の問題を示す別の画像です。
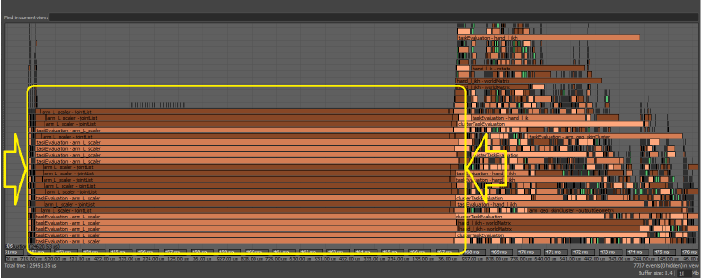
- この場合、いくつかのスレッドが Python コードを実行していたため、グローバル インタプリタ ロック(GIL)が使用可能になるまで、これらが待機する必要がありました。 競合の問題によるボトルネックとパフォーマンスの低下は、コンピュータに多数のコアがある場合など、同時実行レベルが高いときにより顕著になることがあります。
競合の問題が発生した場合は、影響を受けるコードを修復してください。上記の例では、ノードのスケジューリングを変更して上記のプロファイル例を次のように変換し、パフォーマンスを回復しています。このため、Python プラグインは既定で[グローバルにシリアライズ]としてスケジュールされています。つまりプラグインは順番に実行するようにスケジュールされ、GIL を待機する複数のスレッドをブロックしません。
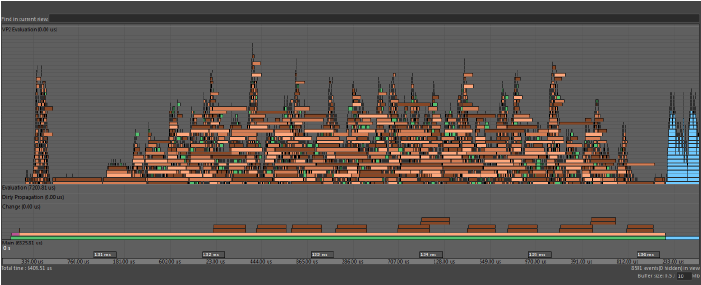
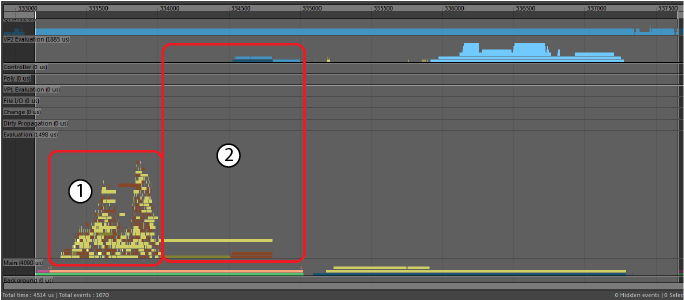
- クラスタ
- 評価グラフにノードレベルの循環依存関係が含まれている場合、それらのノードは、順次スケジュールされる単一の作業単位を表すクラスタにグループ化されます。
- 複数のクラスタを同時に評価できますが、サイズの大きなクラスタでは同時に実行できる作業量が制限されます。プロファイラでは、クラスタは以下に示すように opaqueTaskEvaluation ラベルを持つバーとして識別できます。
-
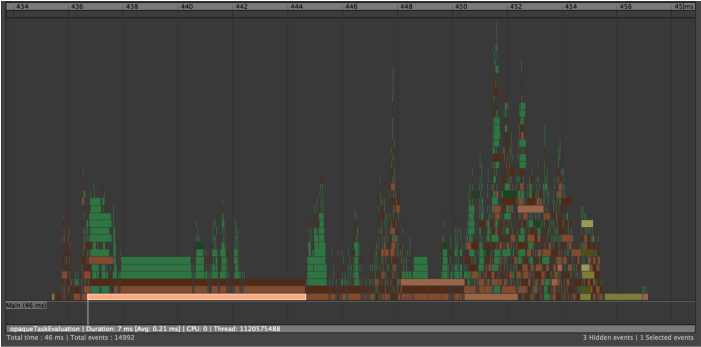
- シーンにクラスタが含まれている場合は、リグ構造を分析して循環性を特定します。理想的には、リグのパーツ間の結合を解除し、リグ セクション(たとえば、頭、ボディなど)を独立して評価できるようにします。
ヒント: シーンのパフォーマンスの問題をトラブルシューティングするときは、評価ツールキットでノードごとに「凍結した」アトリビュートを使用することにより、コストのかかるノードを無効にします。これにより、評価グラフから特定のノードを一時的に削除して、シーン内で正しいボトルネックが特定されたかを簡単に特定できます。
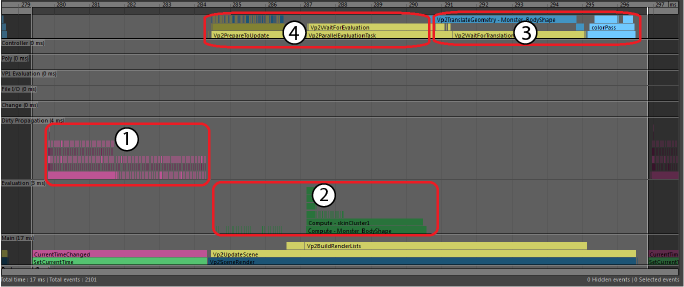
レンダリングにバインドされたパフォーマンス
シーンの主なボトルネックがレンダリングにある場合、シーンは「レンダリングにバインド」と見なされます。次のプロファイラの例は、アニメートされた多くのメッシュを含む大規模なシーンから取得した単一のフレームに拡張されています。オブジェクトの数、各種のマテリアル、ジオメトリの量により、このシーンのレンダリングには大きなコストがかかります。
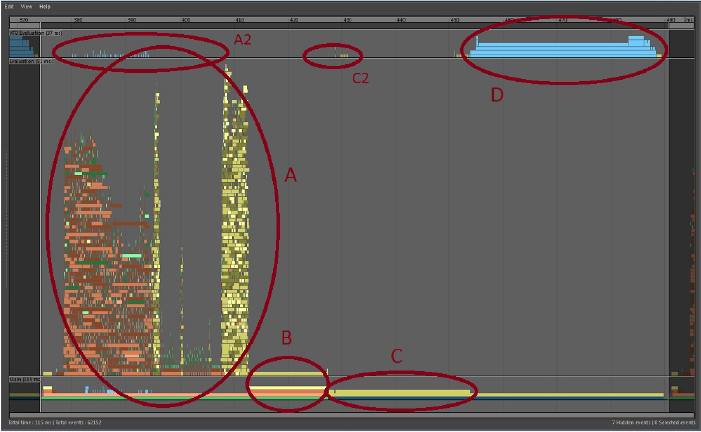
-
- 評価
- GPUOverridePostEval
- Vp2BuildRenderLists
- Vp2Draw3dBeautyPass
このシーンでは多くのメッシュが GPU オーバーライドで評価されているため、一部のプロファイラ ブロックの外観が通常とは異なる場合があります。
- 評価
- 領域 A は、Maya シーンの状態の計算に消費された時間を示しています。この場合は適度に並列化されています。オレンジ色と緑色のシェード付きのブロックは、DG ノードのソフトウェア評価を表します。黄色いブロックは、GPU オーバーライドを介してメッシュ評価を開始するタスクです。GPU のメッシュ評価はこれらの黄色のブロックで始まり、CPU 上の他の作業と同時に続行されます。
- シーン評価における並列ボトルネックの例は、評価セクションの中央のギャップに現れます。右側の大きなグループの GPU オーバーライド ブロックは、シーンの単一の部分に依存しているため、その部分が完了するまで待機する必要があります。
- 領域 A2 (領域 A の上)は、VP2 がシーン評価と並行して行う作業を示す青色のタスク ブロックです。このシーンでは、ほとんどのメッシュ作業は GPU オーバーライドによって処理されるため、ほとんど空になっています。ソフトウェア メッシュを評価するとき、このセクションはレンダリングのためのジオメトリ バッファの準備を示します。
- GPUOverridePostEval
- GPU オーバーライドは、その作業の一部を領域 B で完了します。このブロックに消費される時間は、GPU とドライバの組み合わせによって異なります。GPU の負荷が大きい場合は、ある時点で GPU が評価を完了するまで待機する必要があります。この時間はここに表示されるか、Vp2BuildRenderLists セクションに追加の消費時間として表示されます。
- Vp2BuildRenderLists
- 領域 C。シーンが評価されると、VP2 はレンダリングするオブジェクトのリストを作成します。このセクションの時間は、シーン内のオブジェクトの数に比例します。
- Vp2PrepareToUpdate
- このプロファイルでは、領域 C2 は非常に小さくなります。VP2 はワールドの内部コピーを維持し、それを使ってビューポートで何を描画するかを決定します。シーンをレンダリングするときは、VP2 データベースのオブジェクトが Maya シーンの変更を反映するように修正されていることを確認する必要があります。これらは、たとえば、表示または非表示になったオブジェクト、位置やトポロジが変更されたオブジェクト、などです。これは VP2 Vp2PrepareToUpdate によって行われます。
- シェイプ トポロジ、マテリアル、またはオブジェクトの表示状態の変更があると、Vp2PrepareToUpdate は遅くなります。この例では、シーン オブジェクトには追加の処理がほとんど必要ないため、Vp2PrepareToUpdate はほとんど非表示になります。
- Vp2ParallelEvaluationTask は、この領域に表示される可能性がある別のプロファイラ ブロックです。ここで時間が消費されている場合、オブジェクト評価は評価マネージャのメインの評価セクション(領域 A)から延期され、後で評価されます。このセクションでの評価は、従来の DG 評価を使用します。
- 並列評価中に Vp2BuildRenderLists または Vp2PrepareToUpdate が遅くなる一般的なケースは次のとおりです。
- レンダリングされたオブジェクトの数が多い(この例のように)
- メッシュ トポロジの変更
- レンダリングの前にレガシー評価が必要なイメージ プレーンなどのオブジェクト タイプ
- API コールバックをトリガするサードパーティ プラグイン
- Vp2Draw3dBeautyPass
- 領域 D。すべてのデータの準備が完了すると、シーンがレンダリングされます。ここで、OpenGL または DirectX のレンダリングが行われます。この領域は、深度ピーリング、透明度モード、スクリーン スペースのアンチエイリアシングなど、ビューポート エフェクトに応じてサブセクションに分割されます。
- シーンが以下の状態の場合、Vp2Draw3dBeautyPass が遅くなる場合があります。
- レンダリングするオブジェクトの数が多い(この例のように)
- 透明度を使用する: 既定の透明度アルゴリズムではシーンの統合が効果的に行われないため、透明なオブジェクトが多いとコストがかかる場合があります。透明なオブジェクトの数が非常に多い場合、(VP2 設定で) [透明度アルゴリズム]を[オブジェクトのソート]ではなく[深度ピーリング]に設定すると、処理が高速になる場合があります。テクスチャ マッピング解除モードに切り替えてこのコストを回避することもできます。
- 使用するマテリアルの数が多い: VP2 では、オブジェクトはレンダリングの前にマテリアル別にソートされます。そのため、さまざまなマテリアルが大量に存在すると時間がかかります。
- ビューポート エフェクトを使用する: SSAO (スクリーン スペース アンビエント オクルージョン)、被写界深度、モーション ブラー、シャドウ マップ、または深度ピーリングなどのエフェクトの多くには、追加の処理が必要です。
- その他の検討事項
- 上記の主要なフェーズはすべてのシーンに適用されますが、シーンに応じてパフォーマンスの特性は異なる場合があります。
- アニメーションが制限されている静的シーンの場合、または非変形のアニメートされたオブジェクトの場合は、パフォーマンスを向上させるために統合を使用します。統合により、同じマテリアルを共有するオブジェクトがグループ化され、レンダリングするオブジェクトが少なくなるため、Vp2BuildRenderLists と Vp2Draw3dBeatyPass の両方で消費される時間が短縮されます。
プロファイルの保存と復元
プロファイル データは、またはプロファイラ(Profiler)ウィンドウのを使用して将来の解析のためにいつでも保存することができます。すべてプレーンな文字列データとして保存され、を使用して任意のシーンからプロファイル データをロードできます。