在 ML 变形器训练设置中,您可以配置如何对机器学习模型进行训练数据训练。有关如何导出训练数据的详细信息,请参见 ML 变形器“导出训练数据”(Export Training Data)窗口。
打开 ML 变形器训练设置
- 在 ML 变形器属性(ML Deformer Attributes)选项卡中,单击“训练模型...”(Train Model...)
 图标。
图标。
- 在 ML 变形器属性(ML Deformer Attributes)选项卡中,在“ML 模型”(ML Model)列上单击鼠标右键,然后选择“训练模型...”(Train Model...)
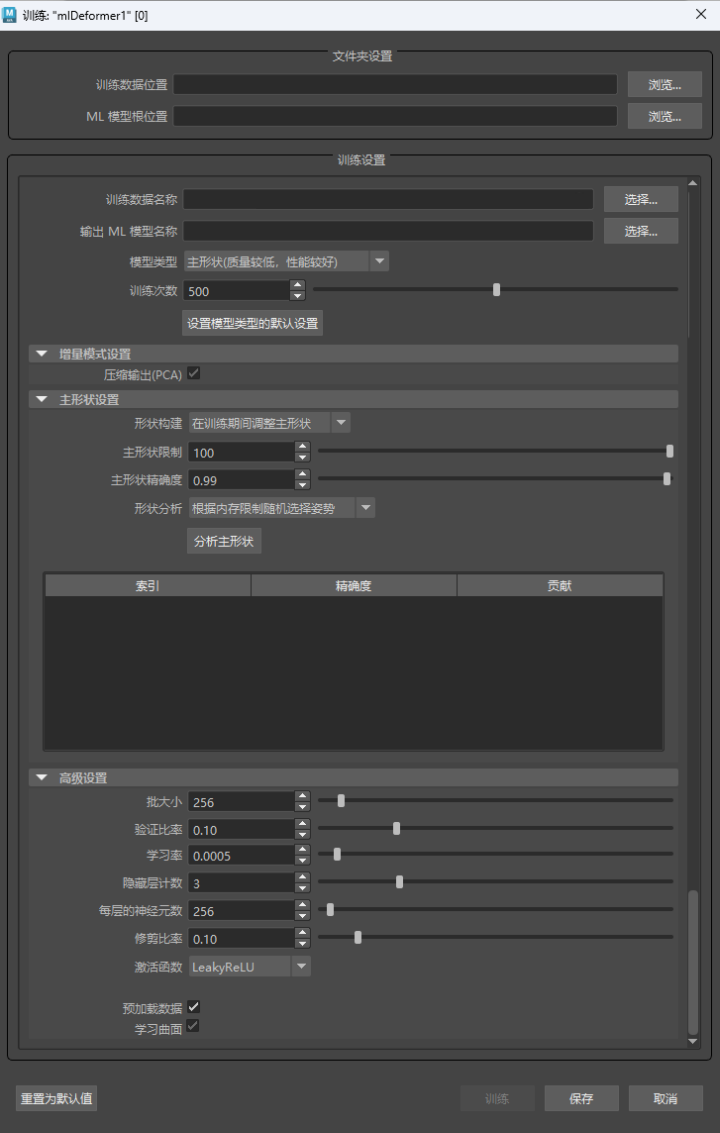
文件夹设置(Folder Settings)
通过此部分,您可以设置导出的训练数据和训练模型的路径。
- 训练数据位置(Training Data Location)
-
显示将对模型进行训练的导出训练数据的路径。有关如何导出训练数据的详细信息,请参见 ML 变形器“导出训练数据”(Export Training Data)窗口。单击“浏览”(Browse)导航到可以加载训练数据的文件夹。注: 这可以是一个临时目录,因为在对模型进行训练后,无需训练数据,除非您想使用相同的数据对其重新训练。
- ML 模型根位置(ML Model Root Location)
- 显示保存训练的 ML 模型的目录,默认情况下,该目录位于项目文件夹内。ML 变形器需要 ML 模型才能运行,因此这些模型通常应与场景保留在同一项目中,以便更轻松地共享。
- 单击“浏览”(Browse)导航到要存储 ML 模型的文件夹。
训练设置(Training Settings)

- 训练数据名称(Training Data Name)
- 指定用于训练模型的训练数据集的名称。这应与在 ML 变形器“导出训练数据”(Export Training Data)窗口中导出训练数据时指定的名称匹配。
- 输出 ML 模型名称(Output ML Model Name)
- 将创建的文件夹的名称,用于保存经过训练的 ML 模型文件及其关联元数据。此文件夹的后缀名为“.mldf”。例如,使用名称“test”进行导出时,将在“训练数据名称”(Training Data Name)目录的“ML 模型根位置”(ML Model Root Location)文件夹中创建一个名为 test.mldf 的文件夹。
- 模型类型(Model Type)
-
“模型类型”(Model Type)下拉菜单允许您为 ML 变形器选择训练方法。所选的模型类型决定了用于学习和近似变形的基本方法。
主形状(质量较低,性能较好)(Principal Shapes (lower quality, better performance)):将 ML 变形器配置为相对于静止姿势为目标变形计算一系列基础增量姿势,而不是逐顶点解算增量。这种方法可以加速训练和解算,但会牺牲准确性。
有关如何使用“主形状”(Principal Shapes)的步骤,请参见使用主形状创建 ML 变形器训练数据。
增量模式(质量较高,性能较慢)(Delta Mode (higher quality, slower performance))(默认设置):使用神经模型直接预测变形增量。这种方法可以产生具有更详细变形的卓越质量,但会导致模型变大且训练/推理时间变长。这是“主形状”(Principal Shapes)处于非活动状态时的默认设置。
PCA 模式(平衡质量和性能)(PCA Mode (balanced quality and performance)):将主成分分析 (PCA) 应用于增量模式输出以压缩变形数据。与原始“增量模式”(Delta Mode)相比,这种混合方法可以保持比“主形状”(Principal Shapes)更好的质量,同时提高性能,使其成为一种中间解决方案。
- 训练次数(Epochs)
- 用于设置训练处理完整数据集的次数。“训练次数”(Epochs)的数量会影响训练模型所花费的时间。
- 设置模型类型的默认设置(Set Default Setting For Model Type)
-
单击此按钮可自动为选定模型类型配置建议设置。这些预设旨在简化设置并确保获得最佳结果。
注意:您可以根据具体工作流的需要覆盖这些默认值。
增量模式设置(Delta Mode Settings)

- 压缩输出(PCA)(Compress Output (PCA))
- 激活以使用主成分分析 (PCA) 对训练输出数据启用降维。启用后,这将减小训练模型文件的大小并提高运行时性能,同时将对变形保真度的影响降至最低。建议对大多数工作流使用此设置。
主形状设置(Principal Shapes Settings)
注意:从“模型类型”(Model Type)下拉列表中选择“主形状(质量较低,性能较好)”(Principal Shapes (lower quality, better performance))时,将启用“主形状”(Principal Shapes)功能。
主形状类似于混合形状:为了创建最终结果,它们具有混合在一起的关联权重。将主形状添加到基础时,它们会重新创建目标变形。这样,ML 变形器使用主形状将控制值映射到这些权重,而不是进行近似增量的训练。
使用主形状非常有用,因为要学习的权重数小于增量数,这样就能更快地学习和解算 ML 模型。(您可能需要减少每层的神经元数,以避免过度拟合。)
主形状是根据训练姿势使用奇异值分解计算出来的。
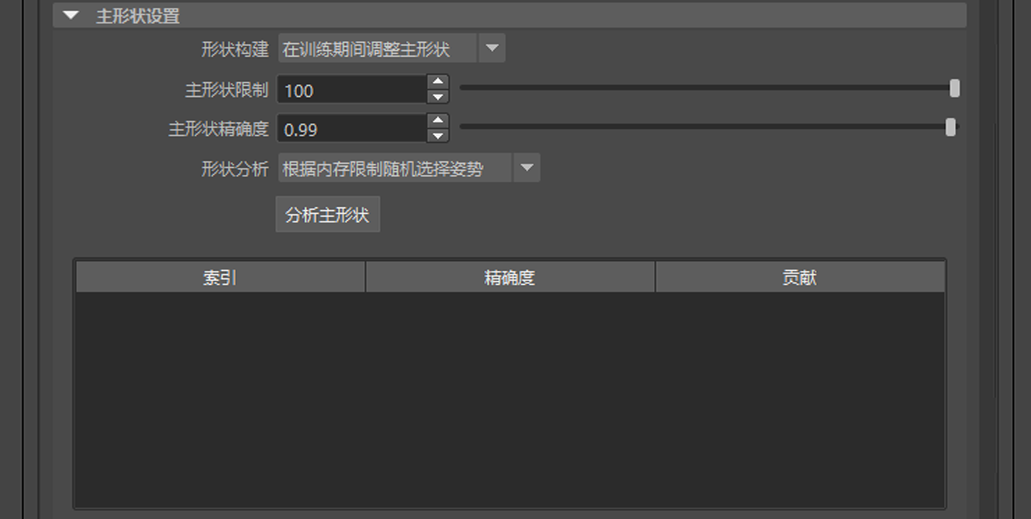
- 形状构建(Shape Construction)
-
变形器学习从主形状重现权重的方式。
固定主形状(Fixed principal shapes):强制模型根据 SVD 分析的学习结果重现权重。
在训练期间调整主形状(Tune principal shapes during training):参数化主形状,允许模型在训练期间对其进行调整。此方法需要更长的时间和更多的内存,但可能会改善结果(尤其是在并非所有训练姿势都适合 SVD 分析的情况下)。这是默认设置。
- 主形状限制(Principal Shapes Limit)
-
要生成的最大主形状数。此值充当硬限制,因此即使未达到所需精度,计算最多也只能使用这么多形状。如果训练数据中的采样数超过增量数,则会显示错误消息。
- 主形状精确度(Principal Shapes Accuracy)
-
主形状组合在采样姿势中应达到的精确度级别。然后,ML 变形器将生成重新创建目标变形以满足此精确度级别所需的主形状数。
注意:这是使用完美权重值的精确度,因此训练模型得出的结果将不太精确。
- 形状分析(Shape Analysis)
-
当所有训练姿势都不适合内存时处理主形状的方式。
尝试使用所有姿势(Attempt to use all poses):
尝试按照添加姿势的顺序使用所有姿势,如果达到内存限制,则显示错误。
根据内存限制截断姿势(Truncate poses to memory limit):尝试按照添加姿势的顺序使用所有姿势,直到达到内存限制(截断其余姿势)。这将导致一些数据丢失。
根据内存限制随机选择姿势(Randomly select poses to memory limit):以随机顺序使用姿势,直到达到内存限制(截断其余姿势)。这将导致一些数据丢失,但会给出数据集相对全面的表示。
高级设置(Advanced Settings)

- 批大小(Batch Size)
-
指定将数据集分为的“批”的大小。这些批一起加载到内存中,因此您需要足够的 RAM(如果使用 GPU,则还需要 VRAM)来支持指定的批大小。
- 验证比率(Validation Ratio)
-
指定应留待验证的训练数据样例的百分比。验证集是训练数据的随机采样,不会用于训练。它提供了一个有用的指标,说明模型在其未见过的数据上的表现如何,也可用于检查是否存在过度拟合。
- 学习率(Learning Rate)
-
配置模型每批必须执行的学习“步骤”的大小,以根据该批的结果进行自身调整。值越小,所需的训练次数越多,可能会过载,而值越大,混乱程度越大,可能无法生成良好的近似。
- 隐藏层计数(Hidden Layer Count)
-
神经网络中的层数,不包括输入层和输出层。当前,所有设置均统一应用于每个隐藏层。
- 每层的神经元数(Neurons per Layer)
-
应存在于模型每层中的人造神经元数。这些神经元从上一层获取一组输入值,并生成输出值。增加神经元数使模型能够学习更多的变形。
- 修剪比率(Dropout Ratio)
-
使用“修剪比率”(Dropout Ratio)可帮助防止过度拟合。使用“修剪比率”(Dropout Ratio)时,在训练期间,每个层的比率设置的输入部分将设置为零。
- 激活函数(Activation Function)
-
选择要应用于神经元输入总和以生成输出的函数。这些函数为输出引入了非线性,使模型能够学习输入和输出之间的非线性关系。
- 预加载数据(Preload Data)
-
激活以在训练过程中将所有训练数据加载到内存中,而不是批量加载。如果训练数据集能够完全放入内存中,则建议启用“预加载数据”(Preload Data),因为这样会使训练过程明显加快。
- 学习曲面(Learn Surface)
-
激活以使用额外的顶点帧训练变形器,而不是让模型猜测增量和曲面。这可以改善噪波结果。若要使用该选项,请确保“增量模式”(Delta Mode)设置为“曲面”(Surface),并在“导出训练数据”(Export Training Data)设置中启用“导出曲面信息”(Export Surface Information)。

“学习曲面(”Learn Surface)禁用对比“学习曲面”(Learn Surface)启用