Voice デバイスは、任意の言語を使用してリアルタイムで同時に最大 2 つのキャラクタの唇の動きを同期化できる音声認識とサウンド分析を提供します。また、オーディオ ファイルまたはライブ オーディオ入力をモデルにリンクさせ、さまざまなサウンド プロパティを抽出することもできます。
Voice デバイスはオーディオ入力の特定の音素を識別するので、キャラクタ フェースに接続すると、キャラクタのヘッド モデルのシェイプ(形状)を制御して、モデルの口をオーディオに合わせて動かすことができます。
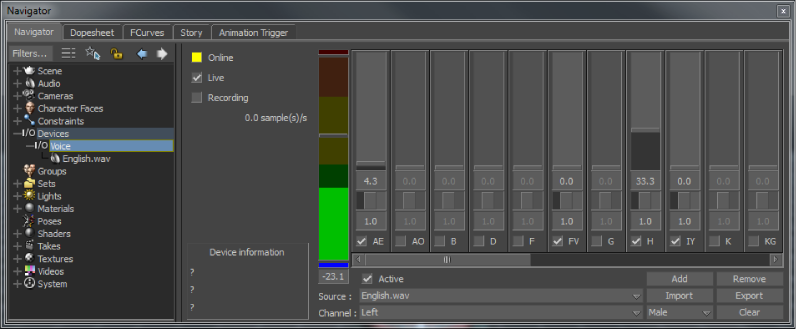
Navigator ウィンドウでの Voice デバイス設定
注: Voice デバイスを使ってフェーシャル アニメーションを制御する前に、適切な音素のシェイプまたはクラスタ シェイプを含むフェース モデルをロードする必要があります。詳細は、「オーディオドリブン フェーシャル アニメーション ワークフロー」を参照してください。