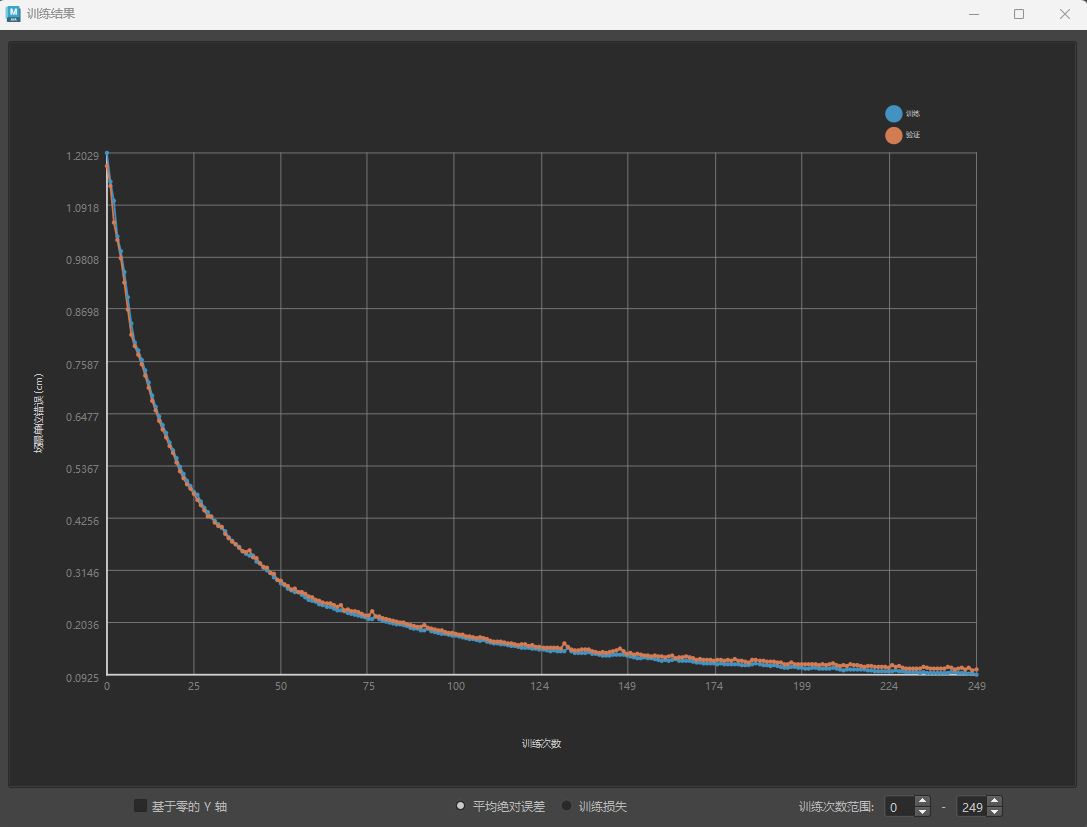
ML 变形器“训练结果”(Training Results)窗口会显示一个包含训练误差率的图表,使您可以识别训练期间影响变形器性能的趋势,例如过度拟合。
打开 ML 变形器“训练结果”(Training Results)窗口
- 在 ML 变形器属性(ML Deformer Attributes)窗口中,在“ML 模型”(ML Model)列上单击鼠标右键,然后选择“查看训练结果...”(View Training Results...)
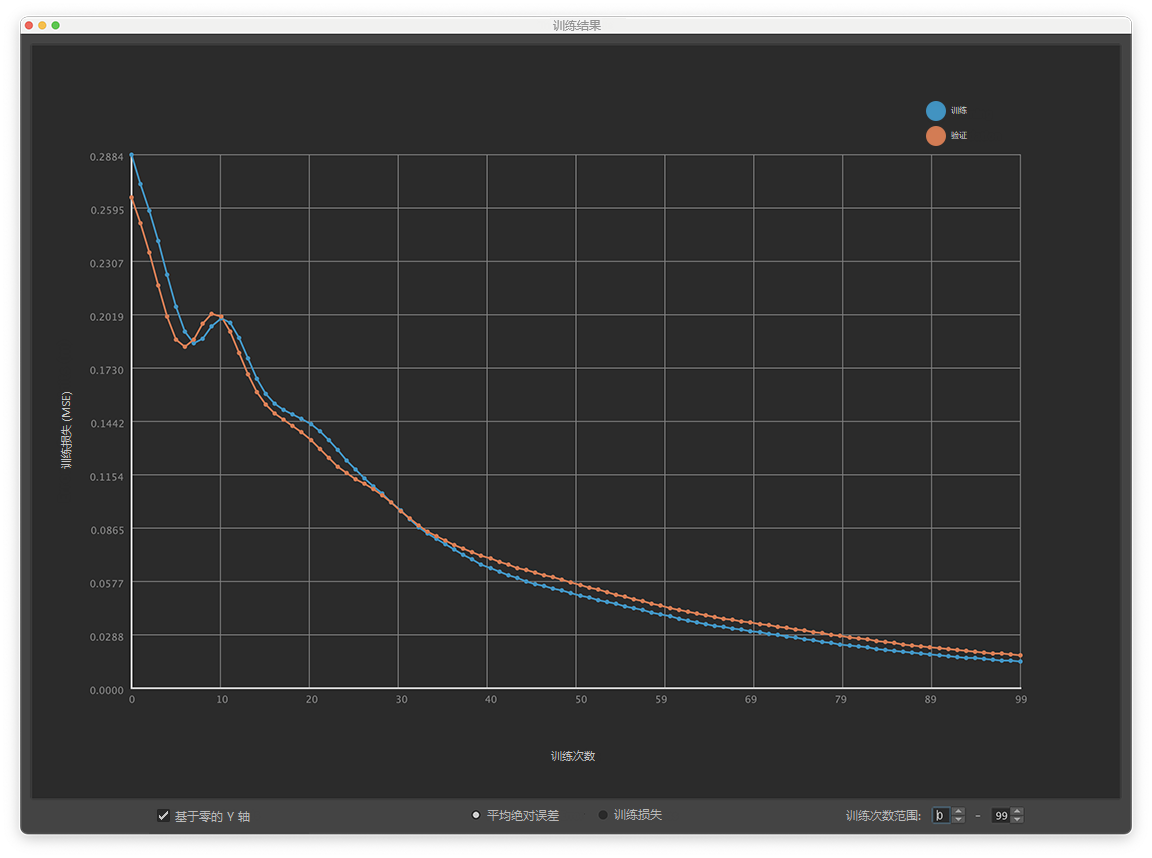
ML 变形器“训练结果”(Training Results)窗口
蓝色线显示训练数据点,橙色线显示验证数据点。
- 基于零的 Y 轴(Zero-based Y-axis)
- 激活此设置可使图表的 Y 轴从零开始。禁用“基于零的 Y 轴”(Zero-based Y-axis),使图表从显示范围内的最小损失处开始。默认设置为活动状态。
- 平均绝对误差(Mean Absolute Error)
- 显示本次训练的所有顶点和采样中生成的增量距目标增量的平均距离,以场景单位(厘米)表示。
-
“平均绝对误差”(Mean Absolute Error)旨在让用户了解训练损失如何转化为场景中的实际结果。但是,由于它是整个经过训练的几何体的平均值,因此如果只有某些区域具有许多变形,则可能会产生误解。
注: 如果使用“主形状”(Principal Shapes),“平均绝对误差”(Mean Absolute Error)不具有直接的实际意义,因为误差值将采用百分比权重而不是增量。
- 训练损失(Training Loss)
- 该图表显示用于训练 ML 变形器的直接损失值。默认情况下,使用平均平方误差计算。
- 训练次数范围(Epoch Range)
- 选择要绘制的训练次数范围,以避免前几次训练会导致整体显示出现严重错误。在训练次数值字段中输入开始和结束范围。
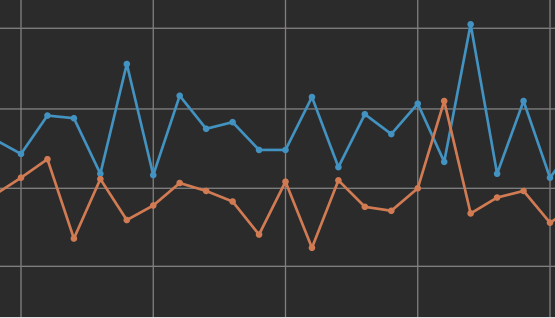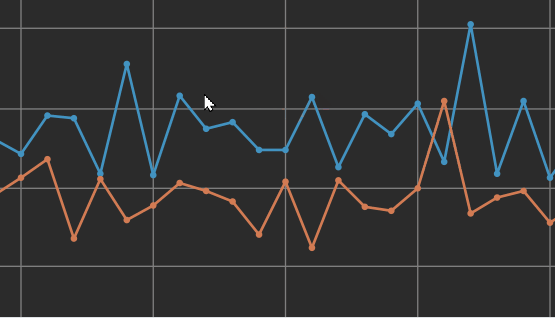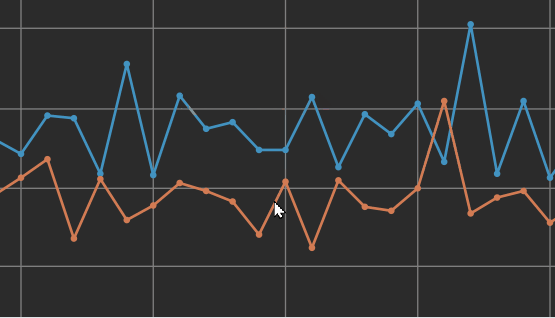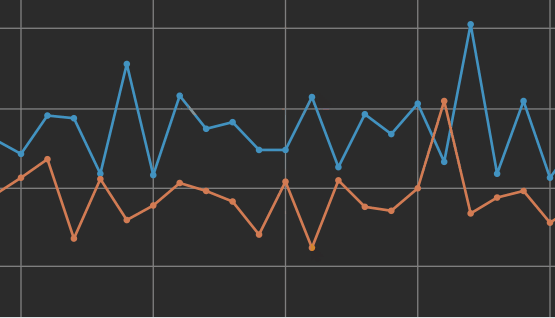
将光标悬停在数据点上可查看各次训练的数据。
过度拟合
过度拟合是一种机器学习概念,当预测结果与现有数据过于相似时会出现过度拟合。当预测模型在训练数据中学习太多细节时,将很难应用到新数据。
举个简单的例子:假设有一条规则按颜色对苹果和桔子进行分类,其中任何红色水果都将标记为“Apple”,而任何橙色水果都将标记为“Orange”。如果该过程遇到绿色苹果,则规则可能会错误地将其标识为“Orange”。出现识别错误是因为规则对初始数据过于严格,无法处理新数据:绿色苹果。这个示例属于过度拟合,说明在进行预测时需要使用多个变量。
在学习过程中,数据可能过度拟合的一个迹象是训练数据与验证数据的误差率之间存在差距。上面的屏幕截图显示了一个明显的过度拟合示例,其中训练数据点和验证数据点之间的差距很大。