The ML Deformer Training settings is where you configure how the Machine Learning model should be trained on the training data. See ML Deformer Export Training Data window for details on how to export the training data.
To open the ML Deformer Training settings
- In the
ML Deformer Attributes tab, click the
Train Model…
 icon.
icon.
- In the ML Deformer Attributes tab, right-click the ML Model column and choose Train Model…
Folder Settings
This section lets you set the path to your exported training data and trained models.
- Training Data Location
-
Shows the path to the exported training data that you will train your model on. See ML Deformer Export Training Data window for details on how to export training data. Click Browse to navigate to a folder where you can load your training data.Note: This can be a temporary directory as the training data is not needed once the model is trained, unless you want to retrain it with the same data.
- ML Model Root Location
- Shows the directory where trained ML models are saved, which is inside the project folder by default. ML models are required for the ML Deformer to function, so they should typically be kept in the same project as the scene to facilitate easier sharing.
- Click Browse to navigate to a folder where you want to store your ML Model.
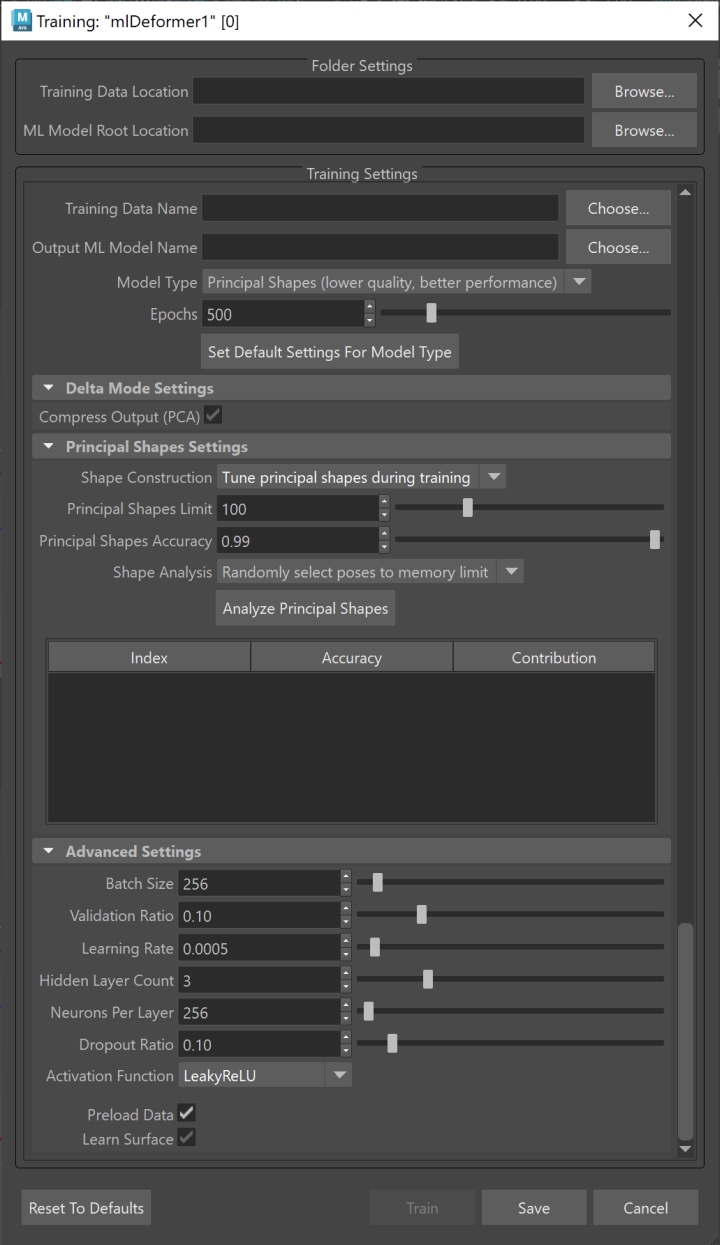
Training Settings
- Training Data Name
- Specifies the name of the training data set to use to train the model. This should match the name specified when exporting the training data in the ML Deformer Export Training Data window.
- Output ML Model Name
- The name of the folder that will be created to hold the trained ML model file and its associated metadata. This folder will be given the suffix ".mldf". For example, exporting with the name "test" will create a folder called test.mldf in the ML Model Root Location folder in the Training Data Name directory.
- Model Type
-
Model Type dropdown allows you to select the training approach for your ML Deformer. The selected model type determines the underlying methodology used for learning and approximating deformations.
Principal Shapes (lower quality, better performance): Configures the ML Deformer to compute a series of base delta poses for target deformations relative to the rest pose, rather than evaluating per-vertex deltas. This method accelerates training and evaluation but sacrifices accuracy.
For steps on how to use Principal Shapes, see Create ML Deformer training data using Principal Shapes.
Delta Mode (default, higher quality, slower performance): Directly predicts deformation deltas using the neural model. This approach yields superior quality with more detailed deformations but results in larger model sizes and slower training/inference times. It is the default when Principal Shapes are inactive.
PCA Mode (balanced quality and performance): Applies Principal Component Analysis (PCA) to Delta Mode outputs to compress the deformation data. This hybrid method maintains better quality than Principal Shapes while improving performance over raw Delta Mode, positioning it as a middle-ground solution.
- Epochs
- Lets you set how many times the training processes the complete data set. The number of Epochs impacts how long it takes to train the model.
- Set Default Setting For Model Type
-
Click this button to automatically configure recommended settings for the selected model type. These presets are intended to streamline setup and ensure optimal results.
Note: You can override these defaults as needed for your specific workflow.
Delta Mode Settings

- Compress Output (PCA)
- Activate to enable dimensionality reduction on training output data using Principal Component Analysis (PCA). When enabled, this reduces the trained model file size and improves runtime performance, with minimal impact on deformation fidelity. This setting is recommended for most workflows.
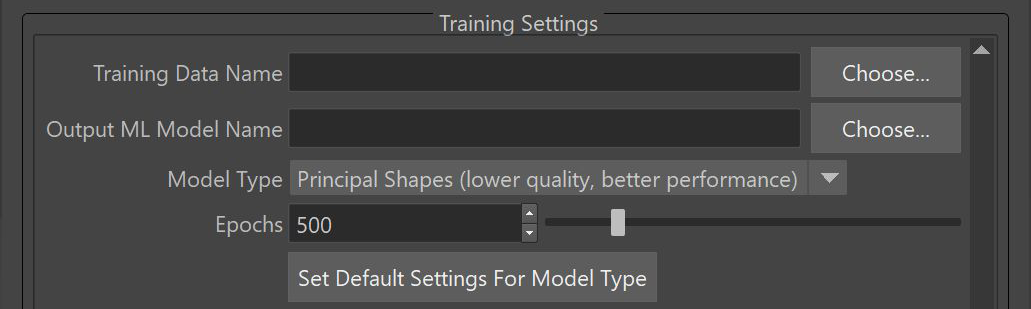
Principal Shapes Settings
Note: Principal Shapes functionality is enabled when Principal Shapes (lower quality, better performance) is selected from the Model Type dropdown.
Principal Shapes are similar to blend shapes: to create the final result, they have associated weights that are blended together. When Principal Shapes are added to the base, they recreate the target deformation. That way, rather than training to approximate deltas, the ML Deformer uses the Principal Shapes to map the control values to these weights.
Using Principal Shapes is useful because the number of weights to learn are smaller than the number of deltas, making the resulting ML model quicker to learn and evaluate. (You may need to reduce the neurons per layer to avoid overfitting.)
Principal Shapes are calculated from training poses using singular value decomposition.
- Shape Construction
-
The manner in which the deformer learns to reproduce weights from principal shapes.
Fixed principal shapes: Forces the model to reproduce weights based on learnings from SVD analysis.
Tune principal shapes during training: Parameterizes the principal shapes, allowing the model to adjust them during training. This method takes longer and requires more memory, but can potentially improve results (especially if not all the training poses fit the SVD analysis). This is the default.
- Principal Shapes Limit
-
The maximum number of Principal Shapes to generate. This value acts as a hard limit, so the computation uses only up to this many shapes even if they do not reach the desired accuracy. An error message appears if there are more samples than deltas in the training data.
- Principal Shapes Accuracy
-
The level of accuracy that the combination of principal shapes should achieve across the sample poses. The ML Deformer then generates the number of Principal Shapes required to recreate the target deformations to meet this level of accuracy.
Note: This is the accuracy using perfect weight values, so the result from the trained model will be less accurate.
- Shape Analysis
-
The manner in which to handle principal shapes when all the training poses don't fit into memory.
Attempt to use all poses:
Attempt to use all the poses in the order they were added and display an error if the memory limit is reached.
Truncate poses to memory limit: Attempt to use all the poses in the order they were added until the memory limit is reached (truncating the rest). This will cause some data loss.
Randomly select poses to memory limit: Use poses in a random order until the memory limit is reached (truncating the rest). This will cause some data loss, but will give a relatively well-rounded representation of the data set.
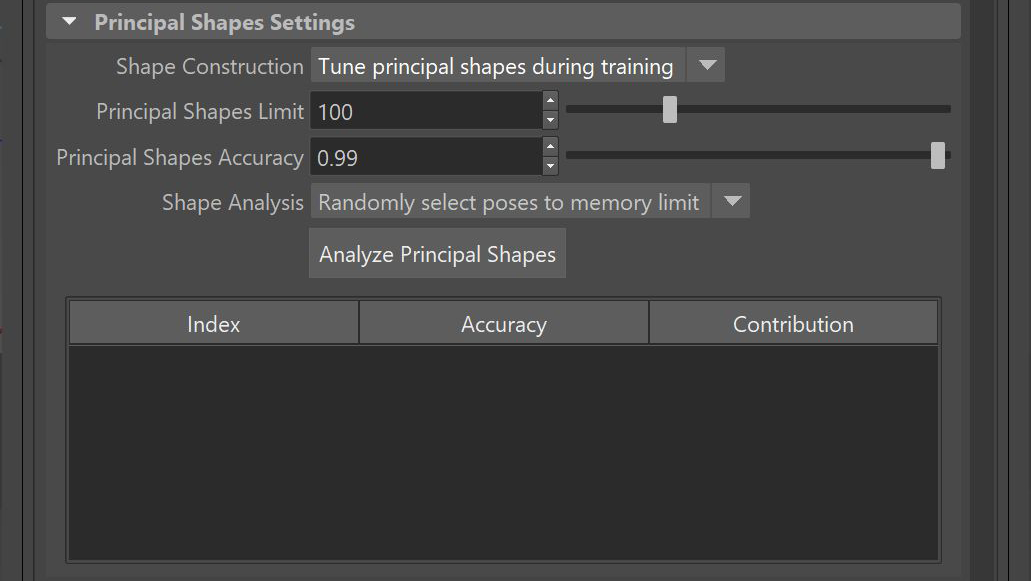
Advanced Settings
- Batch Size
-
Specify a size for the "batches" that the data set is divided into. The batches are loaded into memory together, so you need enough RAM (and VRAM, if using the GPU) to support the specified batch size.
- Validation Ratio
-
Specify the percentage of the training data samples that should be set aside for validation. The validation set is a random sampling of the training data that will not be used to train. It provides a useful indication of how well the model performs on data it hasn't seen, and can also be used to check for overfitting.
- Learning Rate
-
Configure how large a learning "step" the model must take per batch to adjust itself based on the results of that batch. Smaller values require more epochs to train, and can become overloaded, while larger values are more chaotic and may not produce a good approximation.
- Hidden Layer Count
-
The number of layers in the neural network, not including the input and output layers. Currently, all the settings are applied uniformly to each hidden layer.
- Neurons per Layer
-
The number of artificial neurons that should exist in each layer of the model. These neurons take a set of input values from the layer above and produce an output value. Increasing the number of neurons lets the model learn a larger variety of deformations.
- Dropout Ratio
-
Use the Dropout Ratio to help prevent overfitting. When using Dropout Ratio, a fraction of the inputs set by the ratio, for each layer, is set to zero during training.
- Activation Function
-
Choose the function to apply to the sum of a neuron's inputs to generate an output. These functions introduce non-linearity to the output which allows the model to learn nonlinear relationships between the inputs and outputs.
- Preload Data
-
Activate to load all of the training data into memory, instead of loading it in batches, during the training process. Enabling Preload Data is recommended if your training data set is able to fit entirely in memory, as this makes the training process significantly faster.
- Learn Surface
-
Activate to train the deformer with additional vertex frames, rather than having the model guess the deltas and the surface. This can improve noisy results. To use it, make sure that Delta Mode is set to Surface and Export Surface Information is enabled in the Export Training Data settings.
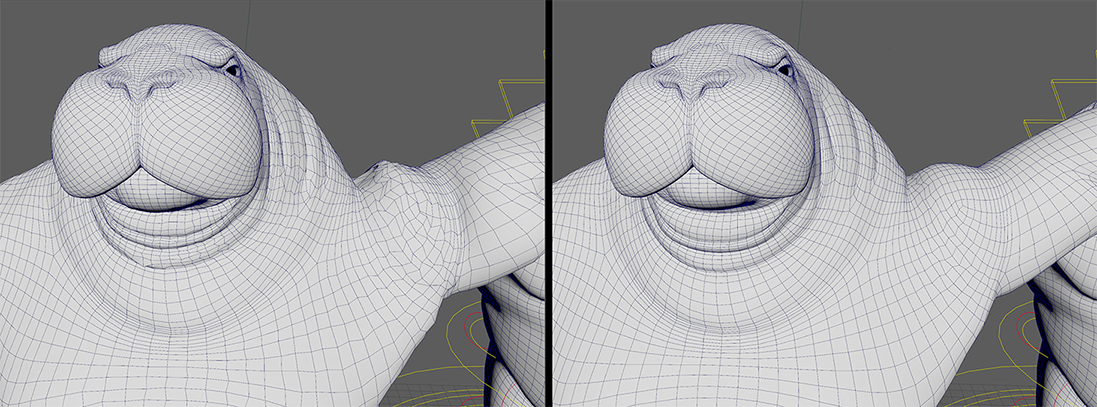
Learn Surface: Off vs Learn Surface: On