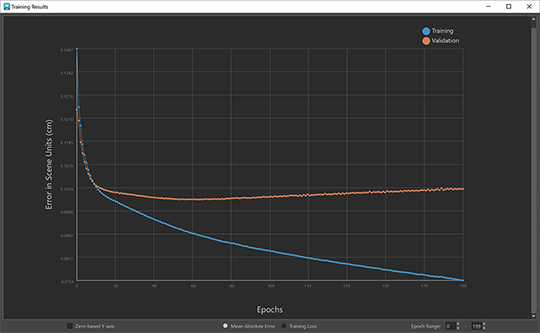
ML デフォーマのトレーニング結果を書き出し(ML Deformer Export Training Results)ウィンドウにはトレーニング エラー率のグラフが表示され、トレーニング中のデフォーマのパフォーマンスに影響する傾向(過剰適合など)を特定できます。
ML デフォーマのトレーニング結果(Training Results)ウィンドウを開くには
- ML デフォーマ アトリビュート(ML Deformer Attributes)ウィンドウで、ML モデル(ML Model)列を右クリックしてトレーニング結果を表示...(View Training Results...)を選択します。
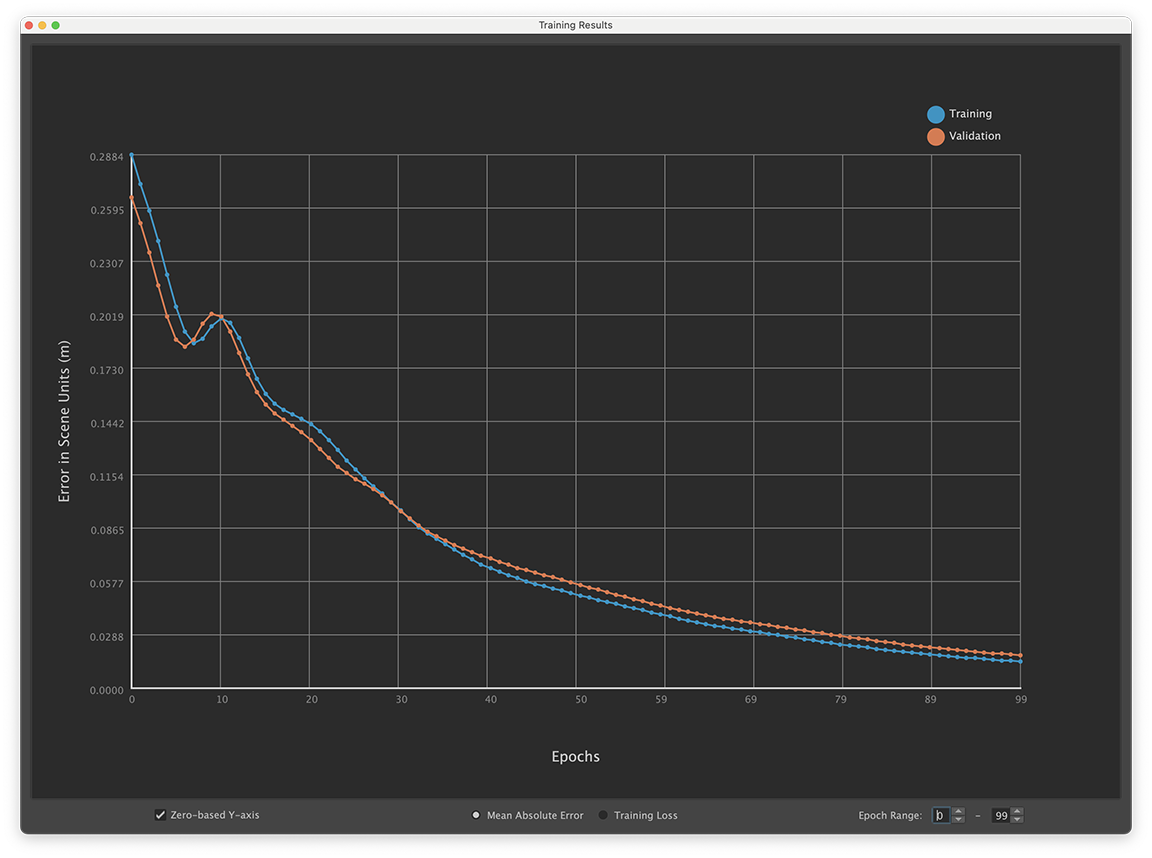
ML デフォーマ トレーニング結果ウィンドウ
青い線はトレーニング データのポイントを示し、オレンジ色の線は検証データのポイントを示します。
- ゼロベースの Y 軸(Zero-based Y-axis)
- この設定を有効にすると、グラフの Y 軸がゼロから始まります。グラフを表示範囲内の最小損失から開始するには、ゼロベースの Y 軸(Zero-based Y-axis)をオフにします。既定の設定はアクティブ(active)です。
- 平均絶対誤差(Mean Absolute Error)
- 生成されたデルタがターゲット デルタからどのくらい離れているかの平均を、シーン単位(センチメートル)で、そのエポックのすべての頂点とサンプルにわたって表示します。
-
平均絶対誤差(Mean Absolute Error)は、トレーニングの損失がシーン内の実際の結果にどのように影響するかを把握するためのものです。ただし、トレーニング済みジオメトリ全体で平均化されるため、特定の領域のみに多くのデフォメーションがある場合は、誤解を招く可能性があります。
注: 平均絶対誤差(Mean Absolute Error)は、主要シェイプ(Principal Shapes)を使用している場合は、物理的には直接的な意味がありません。これは、エラーの値はデルタではなくパーセンテージ ウェイトで表されるためです。
- トレーニング損失(Training Loss)
- グラフには、ML デフォーマのトレーニングに使用された直接損失の値が表示されます。既定では平方平均誤差の計算が使用されます。
- エポック範囲(Epoch Range)
- 印刷するエポックの範囲を選択して、最初のいくつかのエポックで表示全体が歪められるような大きなエラーが生じるのを回避します。エポック(Epoch)値フィールドに開始(Start)と終了(End)の範囲を入力します。
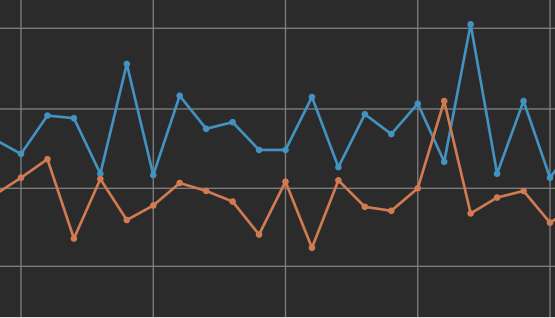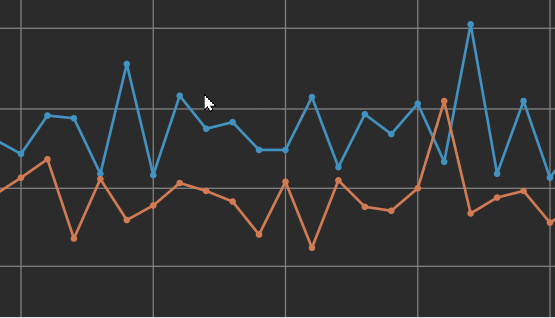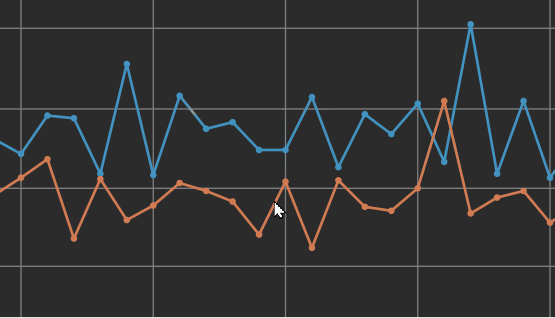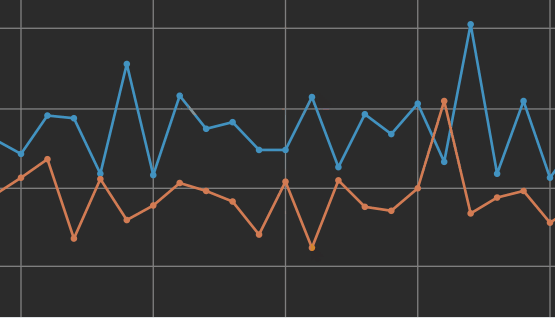
個々のエポックに関するデータを表示するには、データ ポイントにカーソルを合わせます。
過剰適合
過剰適合は、予測が既存のデータに類似しすぎた場合に発生する機械学習の概念です。予測モデルがトレーニング データの詳細を学習し過ぎると、新しいデータに適用するのが困難になります。
簡単な例: リンゴとオレンジを色で分類するルールを考えてみます。赤い果物には「Apple」というラベルが付けられ、オレンジ色の果物には「Orange」というラベルが付けられます。プロセスで青いリンゴが検出されると、誤ってオレンジとして識別される場合があります。識別エラーが発生するのは、ルールが初期データに対して厳密すぎていて、新しいデータ(青いリンゴ)を処理できなかったためです。この例は過剰適合であり、予測を行う場合に複数の変数が必要であることを示しています。
トレーニング中に見られるデータの過剰適合の兆候としては、トレーニング データと検証データのエラー率のギャップがあります。上のスクリーンショットは過剰適合の例を示しています。ここでは、トレーニング データと検証データのポイント間に大きな差異があります。