ML デフォーマのトレーニング データを書き出し(Export Training Data)ウィンドウは、機械学習モデルのトレーニングに必要なデータを書き出すために使用されます。このトレーニング データは、モデルが近似方法を学習している複雑なオリジナルのデフォーマ スタックのサンプル ポーズの形式をとっています。Maya Creative シーンの異なるフレームは、モデルが入力(割り当てられたコントロール)と出力(変形されたジオメトリ)の間の相関関係を決定できるように、異なるポーズで設定する必要があります。これらのサンプル ポーズをランダムに生成する方法の詳細については、「ML デフォーマのコントロール コレクタ(Control Collector)アトリビュート」を参照してください。あるいは、広範囲のモーションを提供する既存のアニメーションをシーンに追加すればトレーニングに十分な場合があり、また、追加のサンプルを提供するためにランダムに生成されたポーズに加えてそれを使用することもできます。
ML デフォーマ(ML Deformer)のトレーニング データを書き出し(Export Training Data)ウィンドウでは、ML デフォーマが学習するためのサンプル ポーズを設定できます。トレーニング データのポーズは、デフォメーション中のさまざまなポイントでのターゲット オブジェクトと ML デフォーマモデルの違いを示すスナップショットです。
ML デフォーマを使用して複雑なデフォメーションをソース オブジェクトに転送する方法については、「ML デフォーマを作成する」および「個別のターゲット ジオメトリを使用して ML デフォーマを作成する」を参照してください。
ML デフォーマのトレーニング データを書き出し(Export Training Data)ウィンドウを開くには
- ML デフォーマ アトリビュート(ML Deformer Attributes)タブで、
 アイコンをクリックします。
アイコンをクリックします。
- ML デフォーマ アトリビュート(ML Deformer Attributes)タブで、ML モデル(ML Model)列を右クリックしてトレーニング データを書き出し...(Export Training Data...)を選択します。
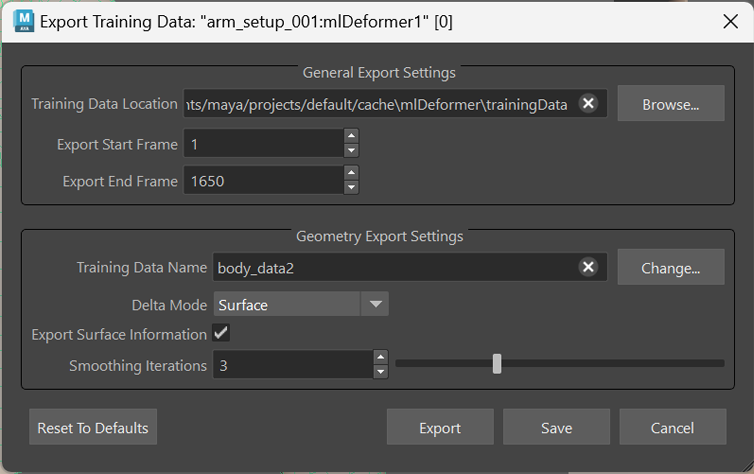
一般的な書き出し設定(General Export Settings)
ML デフォーマのトレーニング データを書き出し(Export Training Data)ウィンドウのこの領域では、書き出し先の場所と、トレーニング セットに使用するシーンのフレーム レンジを設定できます。
- トレーニング データの場所(Training Data Location)
- 参照(Browse)をクリックして、トレーニング データを保存するフォルダに移動します。モデルをトレーニングした後は、同じデータを使用して再トレーニングする場合(たとえば、異なるトレーニング設定をテストする場合)を除いて、トレーニング データは必要ないため、これは一時フォルダにすることができます。
- 開始フレームの書き出し(Export Start Frame)/終了フレームの書き出し(Export End Frame)
- トレーニング データの作成に使用するアニメーションの範囲を指定します。トレーニングに使用するフレームが多いほど、デフォメーション結果の近似がより正確になります。ただし、アニメーションの範囲が広いほど、トレーニングと書き出しのプロセスが遅くなります。
ジオメトリ書き出し設定(Geometry Export Settings)
ML デフォーマのトレーニング データを書き出し(Export Training Data)ウィンドウのこの領域では、書き出されたジオメトリを機械学習モデルで処理するためにどのように表すかを指定できます。
- トレーニング データ名(Training Data Name)
- 書き出されたトレーニング データを含むフォルダの名前を入力します。以前に書き出されたトレーニング データ セットからフォルダを再利用するには、変更(Change)をクリックします。フォルダには、目的を識別しやすくするために、.mltd という接尾辞が付けられます。たとえば、「test」を使用すると、指定したフォルダに test.mltd というフォルダが作成されます。
-
ヒント: トレーニング データ名(Training Data Name)または変更(Change)ボタンにカーソルを合わせると、トレーニング データに関する情報(数、フレーム レンジなど)が表示されます。
- デルタ モード(Delta Mode)
- 書き出されたデータでベース ジオメトリとターゲット ジオメトリの違いを表すモードを設定します。具体的には、元の「ソース」ジオメトリおよび複雑な「ターゲット」ジオメトリ間の「デルタ」が近似されます。ターゲット ジオメトリとソース ジオメトリの違いは、ML デフォーマが最終的に何を学習して予測しようとしているかにあります。次のモードから選択して、デルタの計算と表現方法に対するさまざまなオプションを選択します。
-
注:
- リグによっては、デルタ モード(Delta Mode)をサーフェス(Surface)に設定すると、アーティファクトが生成されたり、不正なジャギーが発生する場合があります。これは、サーフェス頂点フレームが一貫して計算されない場合に発生します(特定のポーズで頂点がオーバーラップしていることが多いため)。トレーニングセットから不正なポーズが削除されると、結果が改善される可能性があります。ただし、ML デフォーマは、トレーニング後もこのようなポーズでパフォーマンスが低下します。
- 多数のコントロールを対象にしてトレーニングを行うと、ML モデルはメッシュの無関係な部分で、コントロールと変形の間にある不正な関連付けを学習する傾向があります。一度にトリガされるコントロールの数が少ないポーズでトレーニングすると、この問題の解決に役立ちます。
-
- オフセット(Offset)
- 長いジョイント チェーンでは問題が生じるため、結果に満足できない場合は、トラブルシューティングの最後の手段としてオフセット(Offset)を使用します。
- オフセット(Offset)の近似には、ローカル回転に基づいて、デフォメーション前の頂点位置とデフォメーション後の頂点位置のオブジェクト空間の差異が使用されます。オフセット(Offset)モードでは、複雑なデルタ計算で発生する可能性のある問題を回避できますが、ML モデルが学習するための処理が増えてより労力がかかります。
- サーフェス(Surface)
- サーフェス(Surface)モードは、各頂点のサーフェスに沿ったディスプレイスメントの観点からデルタを表します。親のトランスフォームは無視されます。このモードは、ディープ ジョイント階層の近似に推奨されます。サーフェス(Surface)モード(既定の設定)では、通常は良好な結果が得られます。ただし、頂点がオーバーラップする場合など、サーフェス(Surface)モードでは不要なアーティファクトが生成される場合があり、これはスムージングの反復(Smoothing Iterations)の値を使用して最小化することができます。
- サーフェス情報を書き出し
- サーフェス情報を書き出し(Export Surface Information)設定を使用して、書き出すデータに追加の頂点フレームを含めます。学習サーフェス(Learn Surface)設定と組み合わせて使用すると、ノイズの多いトレーニング結果を改善することができます。
- スムージングの反復(Smoothing Iterations)
- スムージンのグ反復(Smoothing Iterations)設定を使用して、サーフェス(Surface)のデルタ モード(Delta Mode)を使用する際のアーティファクトを削減します。スムージングの反復(Smoothing Iterations)の値が 0 より大きい場合、デルタ Mush アルゴリズムは書き出し時にジオメトリをスムージングします。
- 既定にリセット(Reset to Defaults)
- トレーニング データを書き出し(Export Training Data)ウィンドウの設定を元に戻します。
- 書き出し(Export)
- このウィンドウで指定した設定を使用して、ML デフォーマのトレーニング データを作成します。完了すると、書き出されたデータに「トレーニング データ名(Training Data Name)」で指定された名前が付けられます。これにより、他のデータと区別したり、後で機械学習モデルをトレーニングするときにトレーニング セットを切り替えることができます。
- 保存(Save)
- 保存(Save)をクリックして、トレーニング データを書き出し(Export Training Data)ウィンドウの現在の設定を保存します。