ML デフォーマのトレーニング設定によって、トレーニング データで機械学習モデルをトレーニングする方法を設定します。トレーニング データを書き出す方法の詳細については、「ML デフォーマ(ML Deformer)のトレーニング データを書き出し(Export Training Data)ウィンドウ」を参照してください。
ML デフォーマのトレーニング設定を開くには
- ML デフォーマ アトリビュート(ML Deformer Attributes)タブで、モデルをトレーニング...(Train Model...)
 アイコンをクリックします。
アイコンをクリックします。
- ML デフォーマ アトリビュート(ML Deformer Attributes)タブで、ML モデル(ML Model)列を右クリックしてモデルをトレーニング...(Train Model...)を選択します。
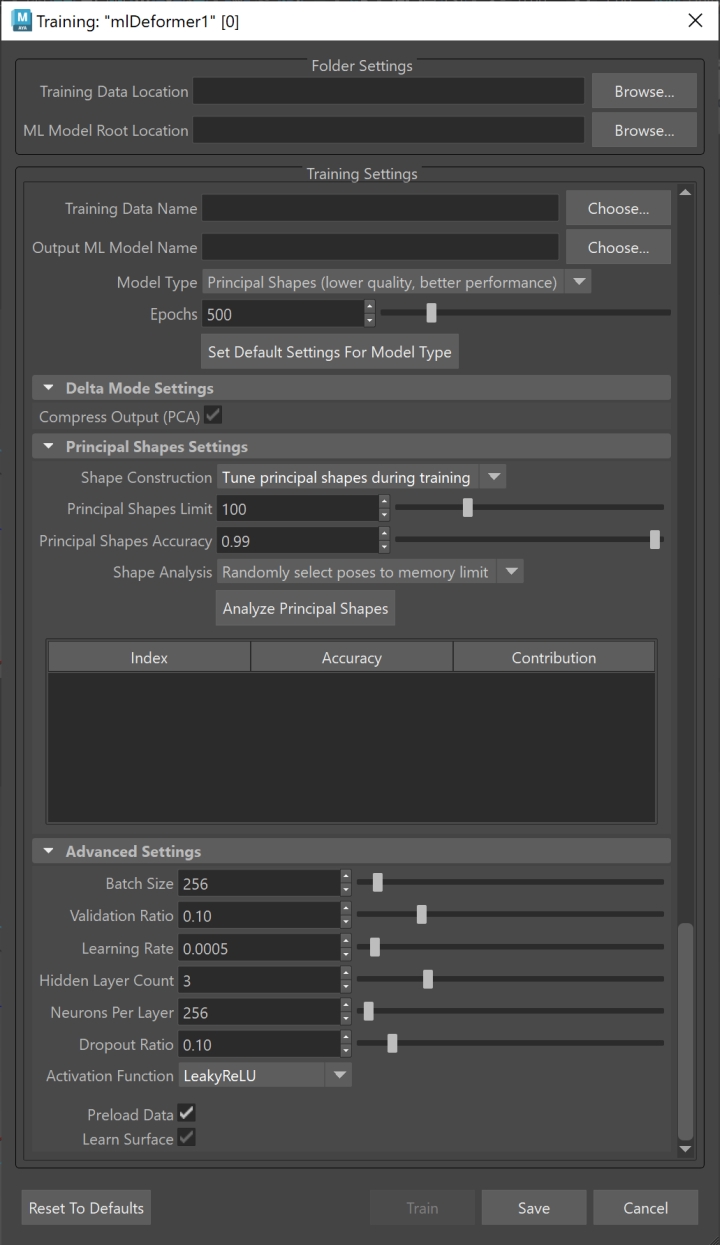
フォルダ設定(Folder Settings)
このセクションでは、書き出したトレーニング データとトレーニング済みモデルへのパスを設定できます。
- トレーニング データの場所(Training Data Location)
-
モデルをトレーニングする書き出されたトレーニング データへのパスを表示します。トレーニング データを書き出す方法の詳細については、「ML デフォーマ(ML Deformer)のトレーニング データを書き出し(Export Training Data)ウィンドウ」を参照してください。参照(Browse)をクリックして、トレーニング データをロードできるフォルダに移動します。注: モデルをトレーニングした後は、同じデータを使用して再トレーニングしない限りトレーニング データは必要ないため、これは一時フォルダにすることができます。
- ML モデル ルートの場所(ML Model Root Location)
- トレーニング済み ML モデルが保存されるフォルダが表示されます。このフォルダは、既定ではプロジェクト フォルダ内にあります。ML デフォーマを機能させるには ML モデルが必要であるため、通常は ML モデルをシーンと同じプロジェクトに保持して、共有しやすくする必要があります。
- 参照(Browse)をクリックして、ML モデルを保存するフォルダに移動します。
トレーニング設定(Training Settings)
- トレーニング データ名(Training Data Name)
- モデルのトレーニングに使用するトレーニング データ セットの名前を指定します。これは、ML デフォーマ(ML Deformer)のトレーニング データを書き出し(Export Training Data)ウィンドウでトレーニング データを書き出すときに指定した名前と一致する必要があります。
- 出力 ML モデル名(Output ML Model Name)
- トレーニング済み ML モデル ファイルとそれに関連付けられたメタデータを保持するために作成されるフォルダの名前。このフォルダには接尾辞「.mldf」が付けられます。たとえば、「test」という名前で書き出すと、Training Data Name フォルダの ML Model Root Location フォルダに test.mldf というフォルダが作成されます。
- モデル タイプ(Model Type)
-
モデル タイプ(Model Type)ドロップダウンで、ML デフォーマのトレーニング方法を選択できます。選択したモデル タイプによって、デフォメーションの学習と近似に使用される基本的な方法が決まります。
主要シェイプ(低品質、高パフォーマンス)(Principal Shapes (lower quality, better performance)): 頂点単位のデルタを評価するのではなく、レスト ポーズを基準にしてターゲット デフォメーションの一連のベース デルタ ポーズを計算するように ML デフォーマを設定します。この方法では、トレーニングおよび評価に要する時間が短縮されますが、精度は低下します。
主要シェイプ(Principal Shapes)の使用手順については、「主要シェイプを使用して ML デフォーマのトレーニング データを作成する」を参照してください。
デルタ モード(高品質、低パフォーマンス)(Delta Mode (default, higher quality, slower performance))(既定): ニューラル モデルを使用して、デフォメーション デルタを直接予測します。この方法では、詳細なデフォメーションを含む高品質の結果が得られますが、モデル サイズが大きくなり、トレーニングと推論の時間が長くなります。主要シェイプ(Principal Shapes)が非アクティブである場合の既定値です。
PCA モード(品質とパフォーマンスをバランス化)(PCA Mode (balanced quality and performance)): デルタ モードの出力に主成分分析(PCA)を適用して、デフォメーション データを圧縮します。このハイブリッド方式では、未加工のデルタ モードよりもパフォーマンスが向上すると同時に、主要シェイプ(Principal Shapes)よりも優れた品質を維持できるため、中間的なソリューションと見なされます。
- エポック(Epochs)
- トレーニングが完全なデータ セットを処理する回数を設定します。エポックの数は、モデルのトレーニング時間に影響します。
- モデル タイプの既定設定を設定(Set Default Settings For Model Type)
-
選択したモデル タイプの推奨設定を自動的に行うには、このボタンをクリックします。これらのプリセットの目的は、設定を合理化し、最適な結果を確保することす。
注: ワークフローによっては、これらの既定値を必要に応じてオーバーライドできます。
デルタ モードの設定(Delta Mode Settings)

- 出力を圧縮(PCA)(Compress Output (PCA))
- アクティブにすると、主成分分析(PCA)を使用してトレーニング出力データの次元を減らすことができます。このオプションがオンの場合、デフォメーションが忠実度に与える影響が最小限になると同時に、トレーニング済みモデルのファイル サイズが小さくなり、実行時のパフォーマンスが向上します。この設定は、ほとんどのワークフローに推奨されます。
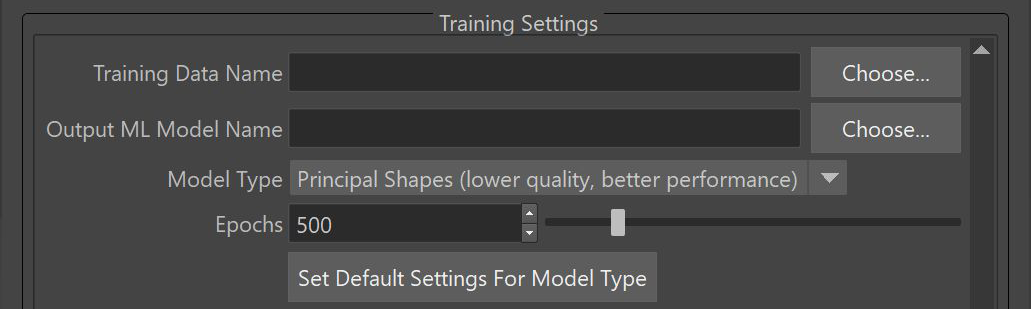
主要シェイプ設定(Principal Shapes Settings)
注: 主要シェイプ(Principal Shapes)機能は、モデル タイプ(Model Type)ドロップダウンで主要シェイプ(低品質、高パフォーマンス)(Principal Shapes (lower quality, better performance))が選択されている場合に有効になります。
主要シェイプ(Principal Shapes)はブレンド シェイプに似ています。最終結果を作成するために、関連付けられたウェイトがブレンドされます。主要シェイプ(Principal Shapes)をベースに追加すると、ターゲット デフォメーションが再作成されます。これにより、ML デフォーマは、デルタを近似するためにトレーニングするのではなく、これらのウェイトにコントロール値をマップするために主要シェイプ(Principal Shapes)を使用するようになります。
主要シェイプ(Principal Shapes)が便利な点は、学習するウェイトの数がデルタの数よりも少なくなり、結果として得られる ML モデルの学習や評価が高速化されるということです。(過剰適合を避けるために、レイヤごとのニューロンの数を減らす必要がある場合があります)。
主要シェイプ(Principal Shapes)は、特異値分解を使用したトレーニング ポーズから計算されます。
- シェイプ コンストラクション (Shape Construction)
-
デフォーマが主要シェイプを基にウェイトを再現する方法をどのように学習するかを決定します。
主要シェイプの修正: SVD 解析から得られた情報に基づき、モデルにウェイトを再現させます。
トレーニング中の主要シェイプの調整: 主要シェイプをパラメータ化し、モデルがトレーニング中に主要シェイプを調整できるようにします。この方法は時間がかかり、より多くのメモリを必要としますが、結果が改善される可能性があります(特に、すべてのトレーニング ポーズを SVD 解析で処理しきれない場合)。これが既定の設定です。
- 主要シェイプの制限
-
生成する主要シェイプの最大数。この値はハード制限として機能するため、目的の精度に達しない場合でも、計算ではこの数のシェイプまでしか使用されません。トレーニング データにデルタよりも多くのサンプルが含まれている場合は、エラー ッセージが表示されます。
- 主要シェイプの精度(Principal Shapes Accuracy)
-
サンプル ポーズ全体で主要シェイプの組み合わせが達成する必要がある精度のレベル。次に、ML デフォーマは、この精度レベルに達するためにターゲット デフォメーションを再作成するのに必要な数の主要シェイプを生成します。
これは完璧なウェイト値を使用した精度であるため、トレーニング済みモデルを使用した場合は精度が低下します。
- シェイプの解析(Shape Analysis)
-
すべてのトレーニング ポーズがメモリに収まりきらない場合に、主要シェイプをどのように処理するかを決定します。
すべてのポーズを使用してみる(Attempt to use all poses):
追加された順序ですべてのポーズを使用することを試します。途中でメモリ制限に達すると、エラーが表示されます。
メモリ制限までポーズを切り捨て(Truncate poses to memory limit): 追加された順序ですべてのポーズを使用することを試します。途中でメモリ制限に達すると、収まりきらなかったポーズは切り捨てられます。これにより、一部のデータが失われます。
メモリ制限までポーズをランダムに選択(Randomly select poses to memory limit): ランダムな順序でポーズを使用します。途中でメモリ制限に達すると、収まりきらなかったポーズは切り捨てられます。これにより、一部のデータが失われますが、データセットを比較的バランスよく表現できます。
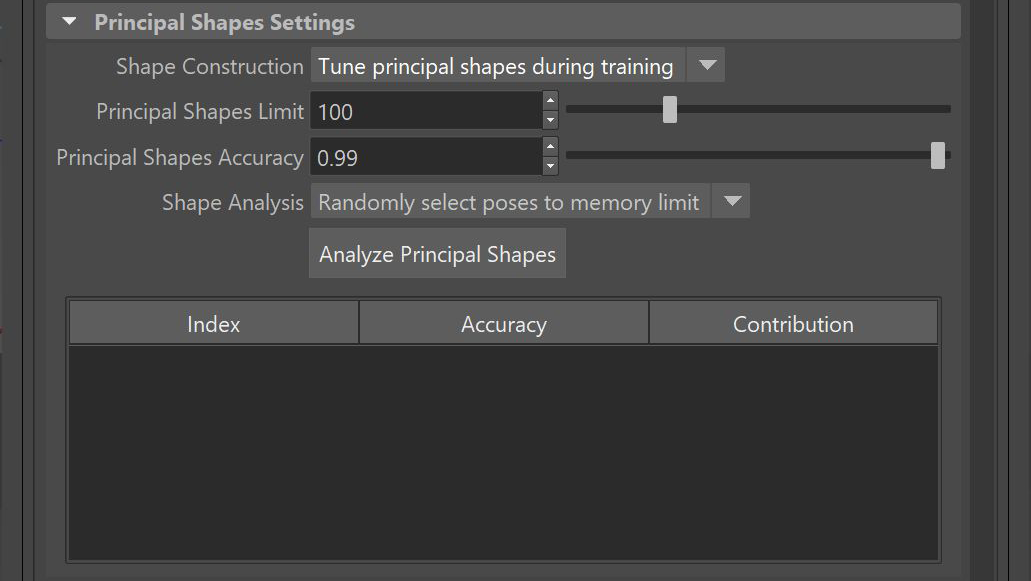
高度な設定(Advanced Settings)
- バッチ サイズ(Batch Size)
-
データ セットを分割する「バッチ」のサイズを指定します。バッチはメモリに同時にロードされるため、指定したバッチ サイズをサポートするのに十分な RAM (および GPU を使用している場合は VRAM)が必要です。
- 検証率(Validation Ratio)
-
検証のために確保する必要があるトレーニング データ サンプルのパーセンテージを指定します。検証セットは、トレーニングに使用しないトレーニング データのランダム サンプリングです。これは、未知のデータに対してモデルがどの程度良好に動作するかを示し、過剰適合のチェックにも使用できます。
- 学習率(Learning Rate)
-
モデルがバッチの結果に基づいてモデル自身を調整するためにバッチごとに実行すべき学習「ステップ」の大きさを設定します。値が小さいほどトレーニングに必要なエポックが増え、過負荷になる場合があります。値が大きいほど無秩序になり、適切な近似が生成されない場合があります。
- 非表示レイヤ数(Hidden Layer Count)
-
入力レイヤと出力レイヤを含まない、ニューラル ネットワークのレイヤ数。現在、すべての設定は非表示の各レイヤに均一に適用されます。
- レイヤあたりのニューロン数(Neurons per layer)
-
モデルの各レイヤに存在する人工的なニューロンの数。これらのニューロンは、上記のレイヤから入力値のセットを取り、出力値を生成します。ニューロンの数を増やすと、モデルはより多くのデフォメーションを学習します。
- ドロップアウト率(Dropout Ratio)
-
ドロップアウト率(Dropout Ratio)を使用して、過剰適合を防ぎます。ドロップアウト率(Dropout Ratio)を使用する場合、各レイヤごとに比率で設定される入力の割合は、トレーニング中にゼロに設定されます。
- アクティベーション関数(Activation Function)
-
ニューロンの入力の合計に適用して出力を生成する関数を選択します。これらの関数は出力に非線形を導入し、モデルが入力と出力の間の非線形の関係を学習できるようにします。
- データをプリロード(Preload Data)
-
アクティブにすると、トレーニング プロセス中にすべてのトレーニング データを一括でロードする代わりに、メモリにロードできます。トレーニング データ セット全体をメモリに収めることができる場合は、データをプリロード(Preload Data)を有効にすることをお勧めします。これにより、トレーニング プロセスが大幅に高速化されます。
- 学習サーフェス(Learn Surface)
-
アクティブにすると、モデルにデルタとサーフェスを推測させるのではなく、追加の頂点フレームでデフォーマをトレーニングできます。これにより、ノイズの多い結果を改善できます。この機能を使用するには、デルタ モード(Delta Mode)がサーフェス(Surface)に設定され、トレーニング データを書き出し(Export Training Data)設定でサーフェス情報を書き出し(Export Surface Information)が有効になっていることを確認します。
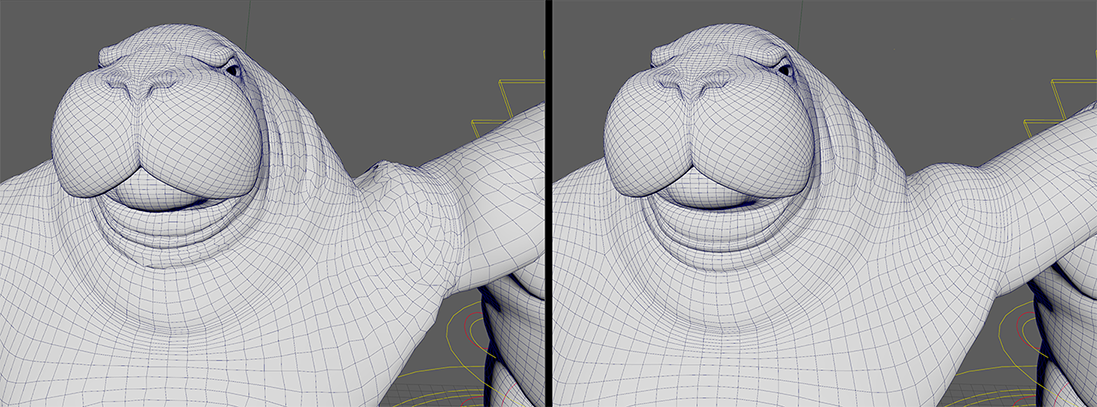
学習サーフェスをオフにした場合(左)とオンにした場合(右)の比較